Principe:
Décoder un base64 corrompu (ignorer les caractères en trop et remplacer le cyrillique par de l'ASCII), assembler les résultats et écouter le flag
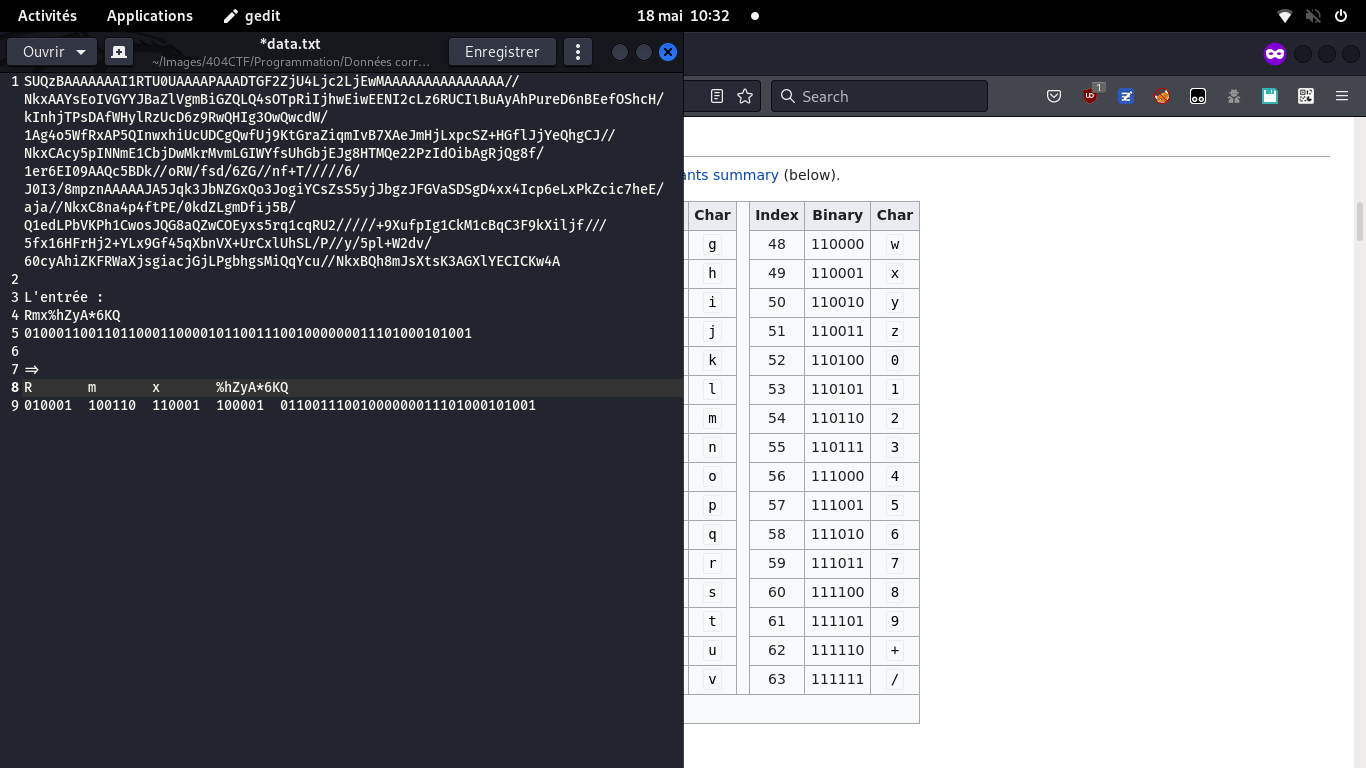
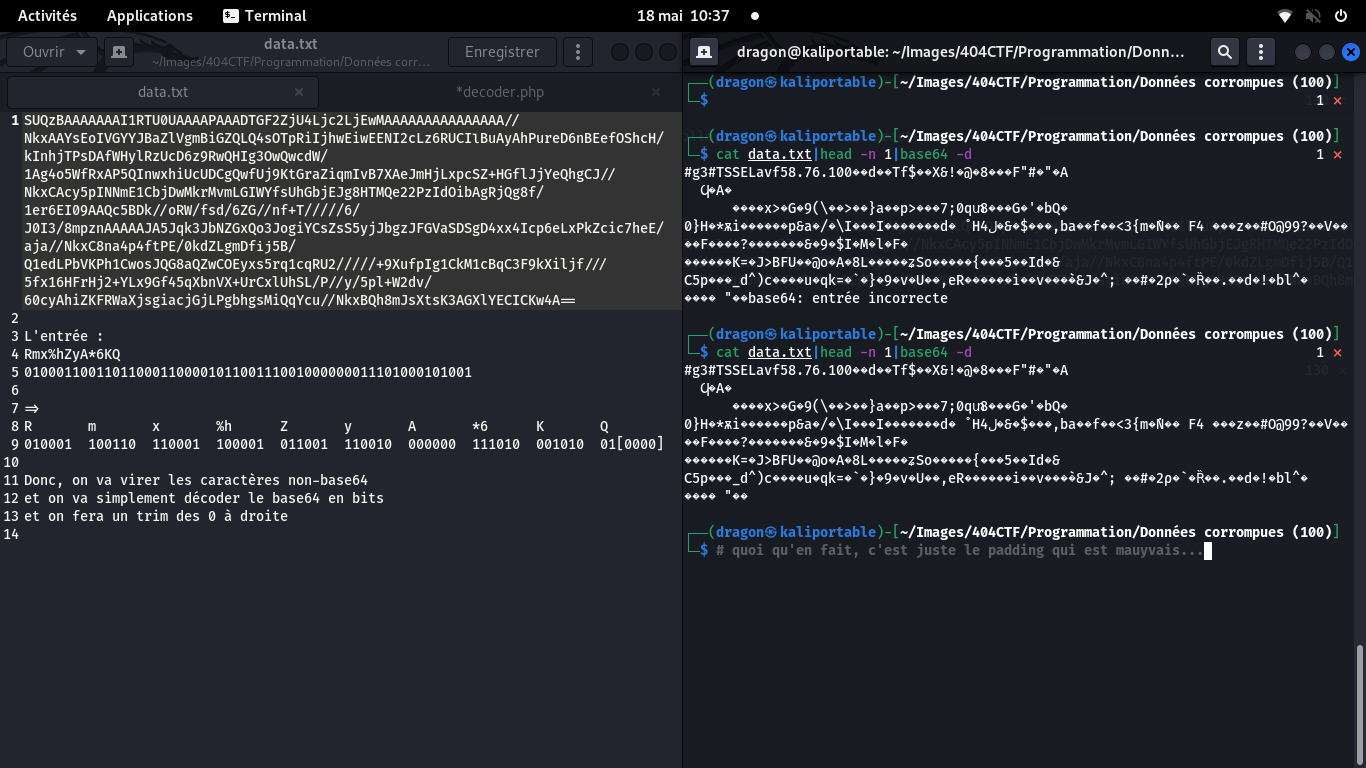
Le challenge nous donne des données, ainsi qu'un exemple partiel de décodage (Rmx%hZyA*6KQ)
J'ai mis en correspondance l'exemple Rmx avec son binaire.
6 bits semblaient être pas mal, puisque cela correspond au base64:
64 valeurs possibles, soit 2**6, donc, 6 bits, c'est bien
Si le Q et R correspondent au base64, le % n'existe pas.
Mais si j'ignore le %, alors le h correspond au base64 100001
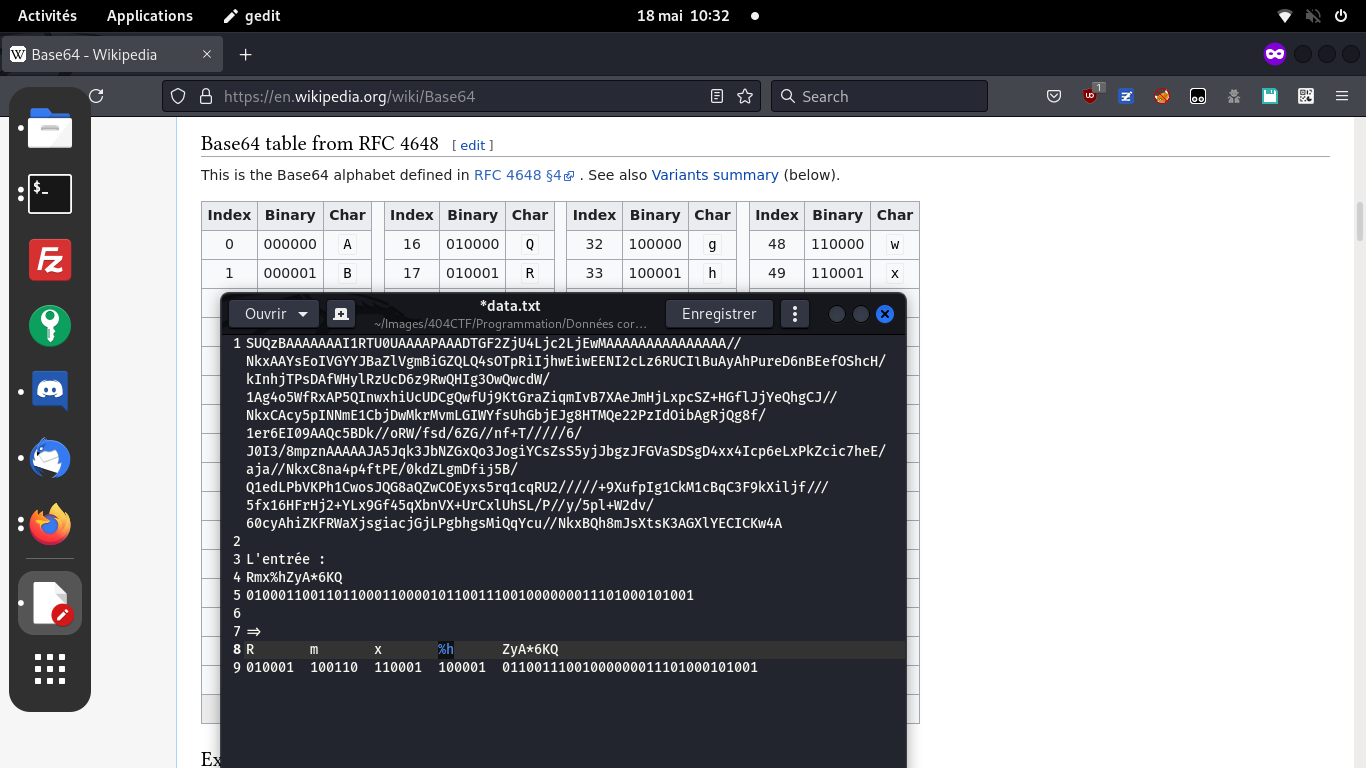
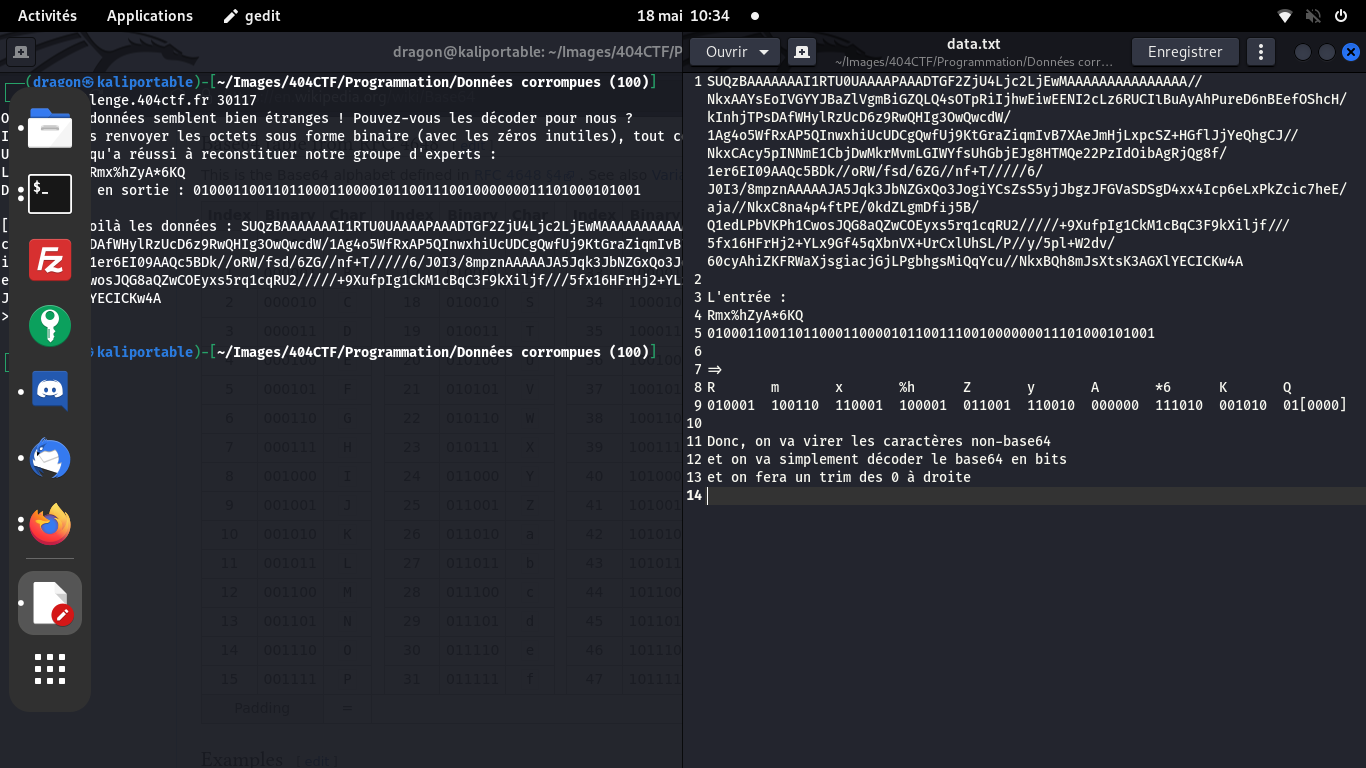
En continuant la mise en relation, on observe simplement que des caractères en trop ont été ajoutés,
et que tous les 0 à droite sont supprimés
Décodage cyrillique
On décode donc le base64 en ignorant les caractères en trop (et en ajoutant le padding de =):
ça donne du verbiage!
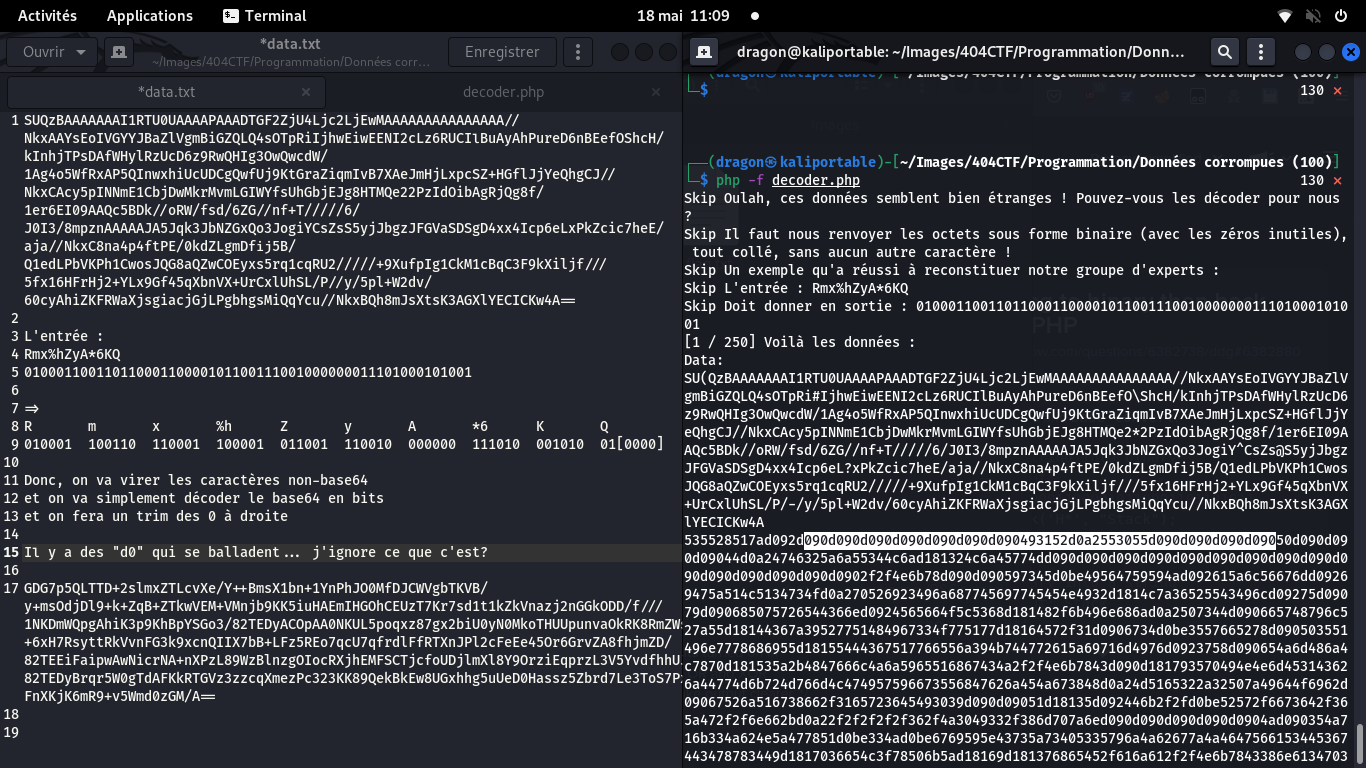
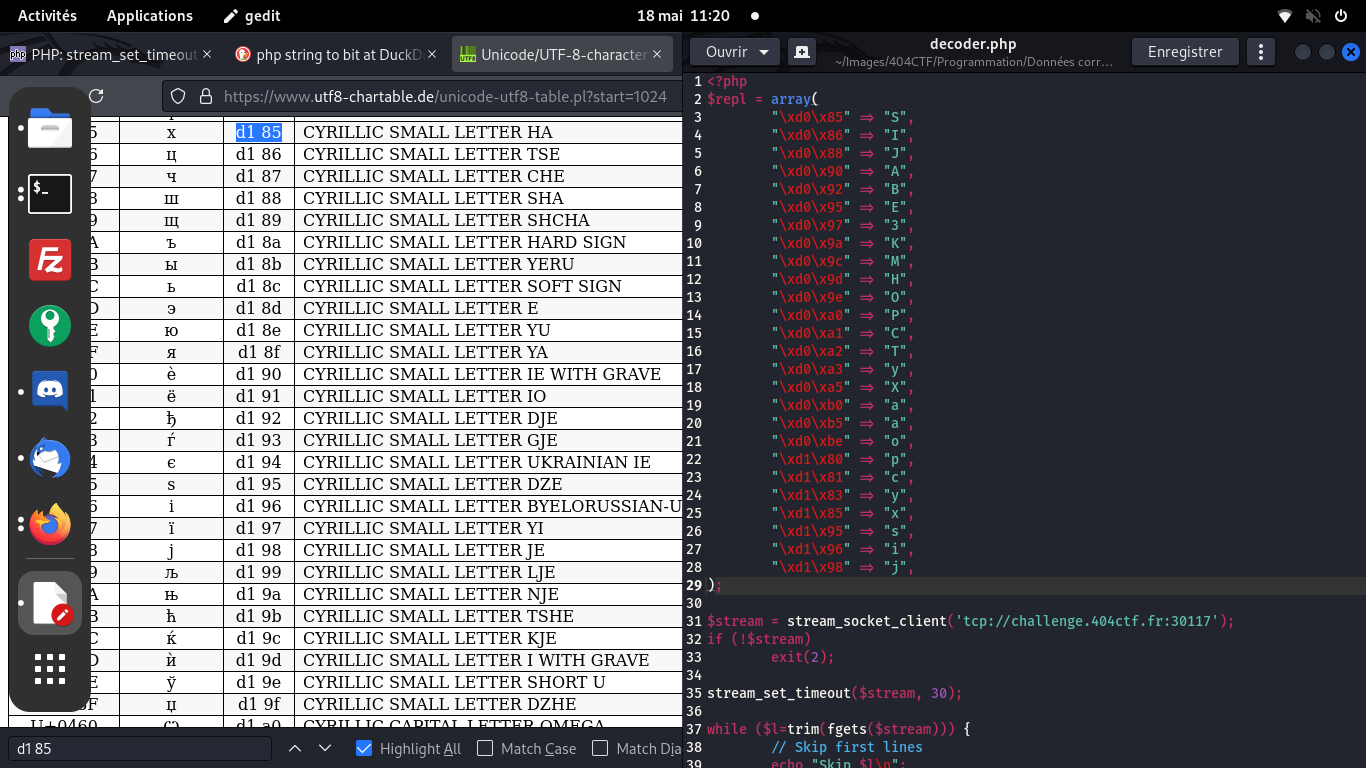
Envisageant que mon script soit planté, je dump alors le code hexa de ce qu'il reçoit,
et surprise! Pleins de 090d apparaissent, ce qui n'est pas du base64!
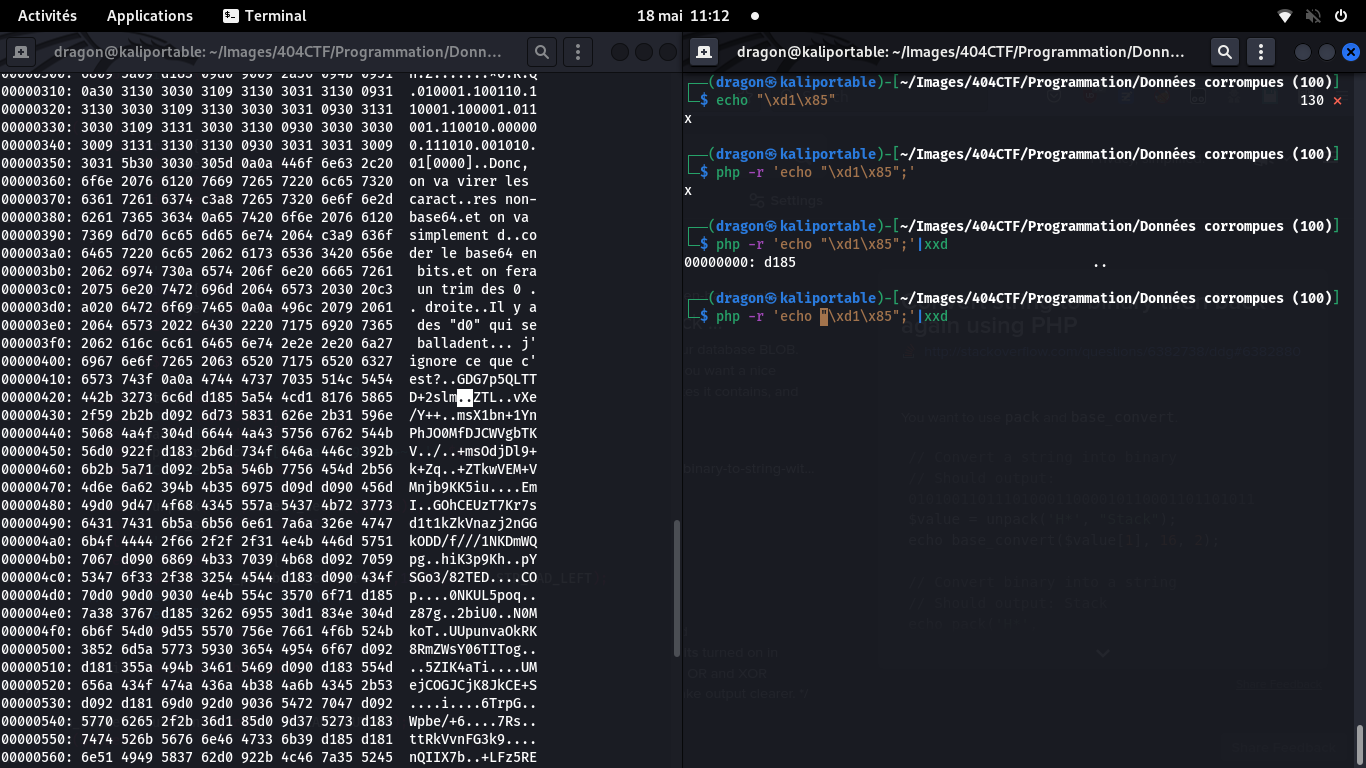
Je reprends les base64 précédents, et je vois d'étranges d185…
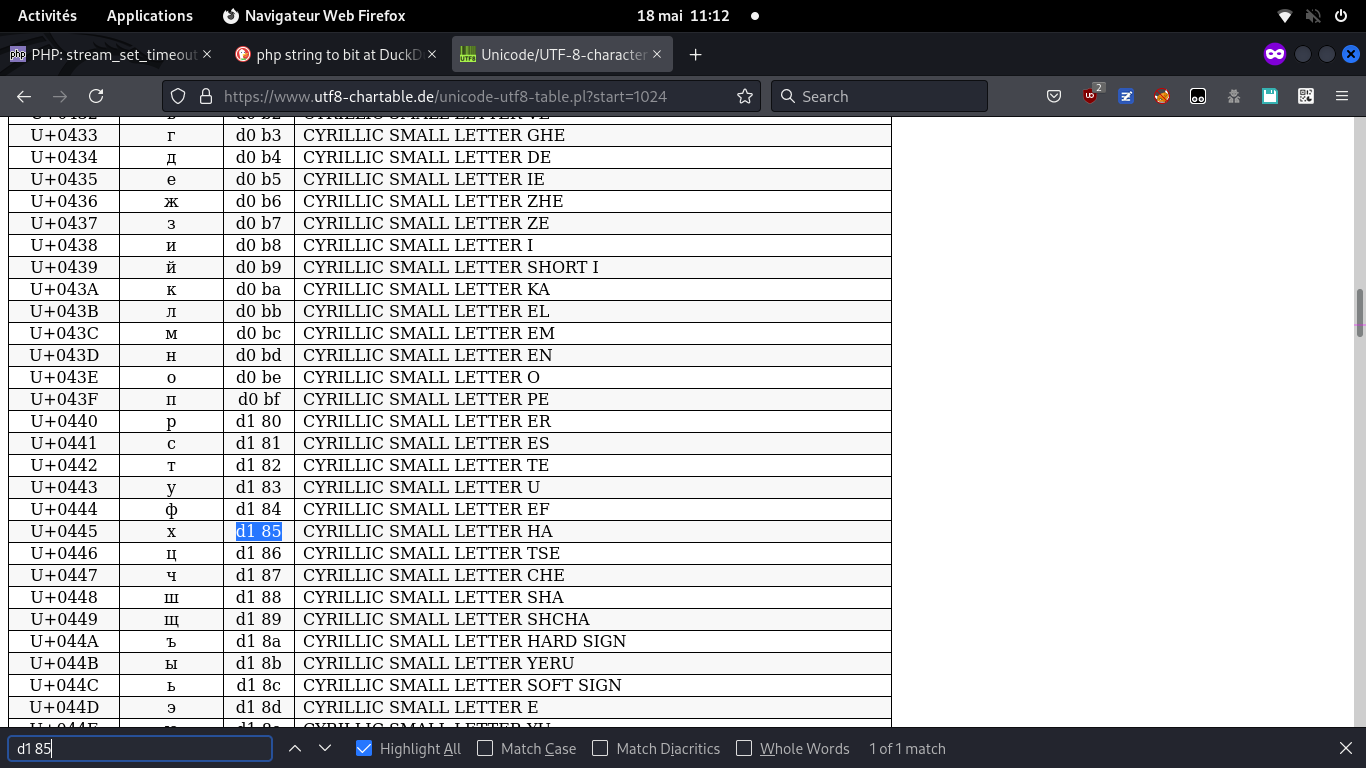
Via un echo, on constate qu'ils ressemblent à des x
Je cherche ce codepoint sur internet et bingo, on voit qu'il s'agit de caractères cyrilliques!
C'est la première fois que je vois un "typo-squatting" dans du base64 :D
Le réflexe d'aller voir le dump hexa me vient
du FCSC 2022
où j'avais loupé un flag à cause de caractères unicodes invisibles
(mais repérables dans un éditeur hexa)
Table cyrillique
Je me construit donc, à la mano, une table de remplacement Cyrillique → Roman
Je pense qu'il existe déjà de telles tables de conversion, mais je n'en ai pas trouvée facilement
pendant ce challenge, alors, je l'ai forgée (et je m'en resservirait peut-être un jour!)
Lancement
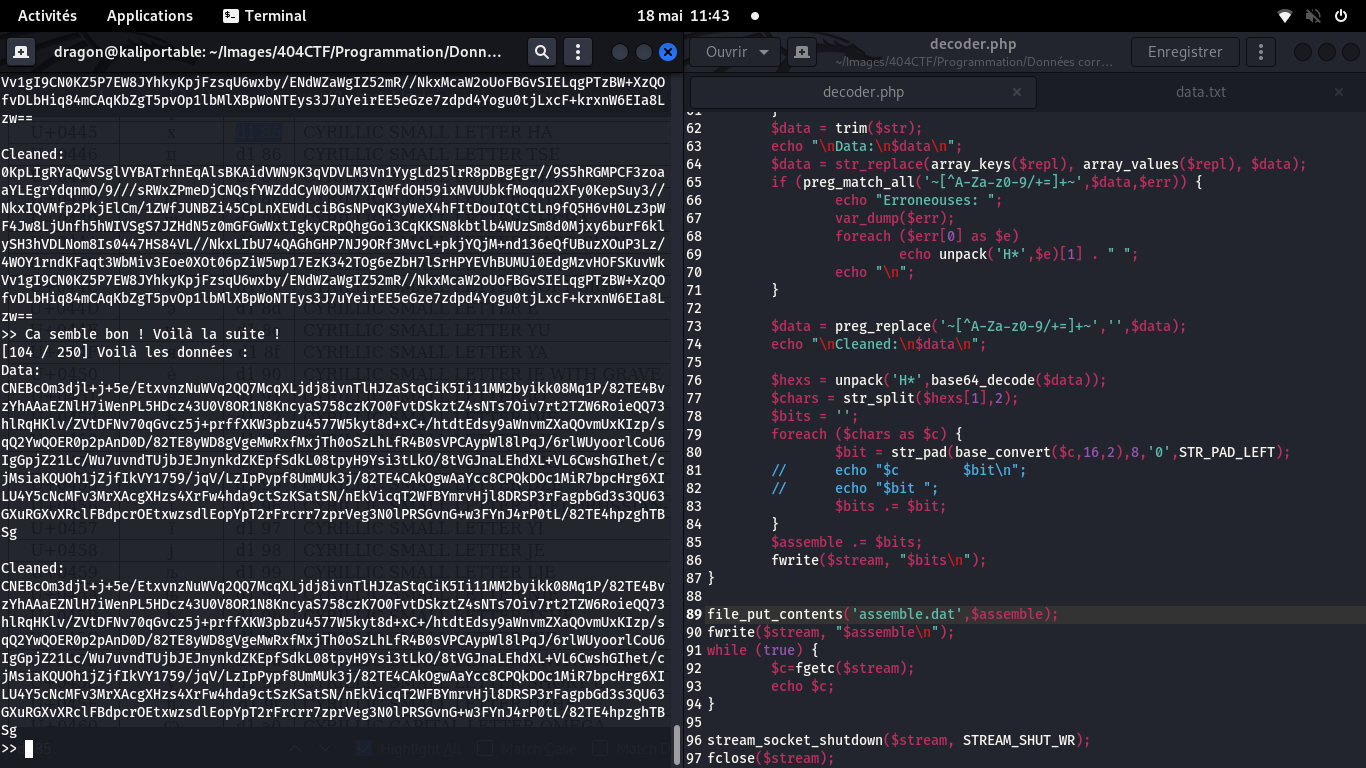
On lance le script, et ça semble marcher! Les données sont lues, corrigées, décodées et retournées
par mon script PHP
Le challenge est réussi, mais zut, il fallait garder ces données de côté pour les réassembler!
Oui, j'ai un broken pipe puisque la connection au serveur de challenge est terminée mais bon,
je ne suis pas là pour faire du dev propre!
Parle-moi
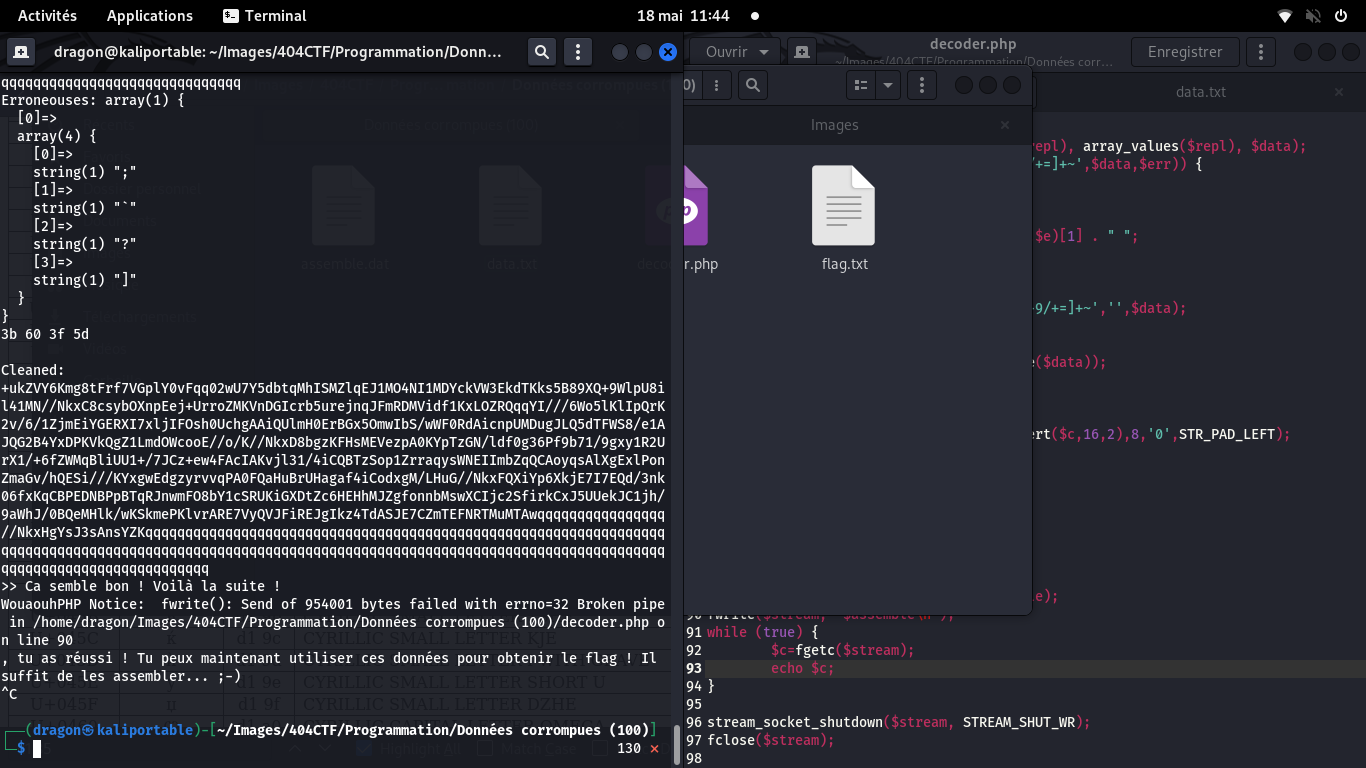
Je corrige donc le script pour stocker et assembler les données,
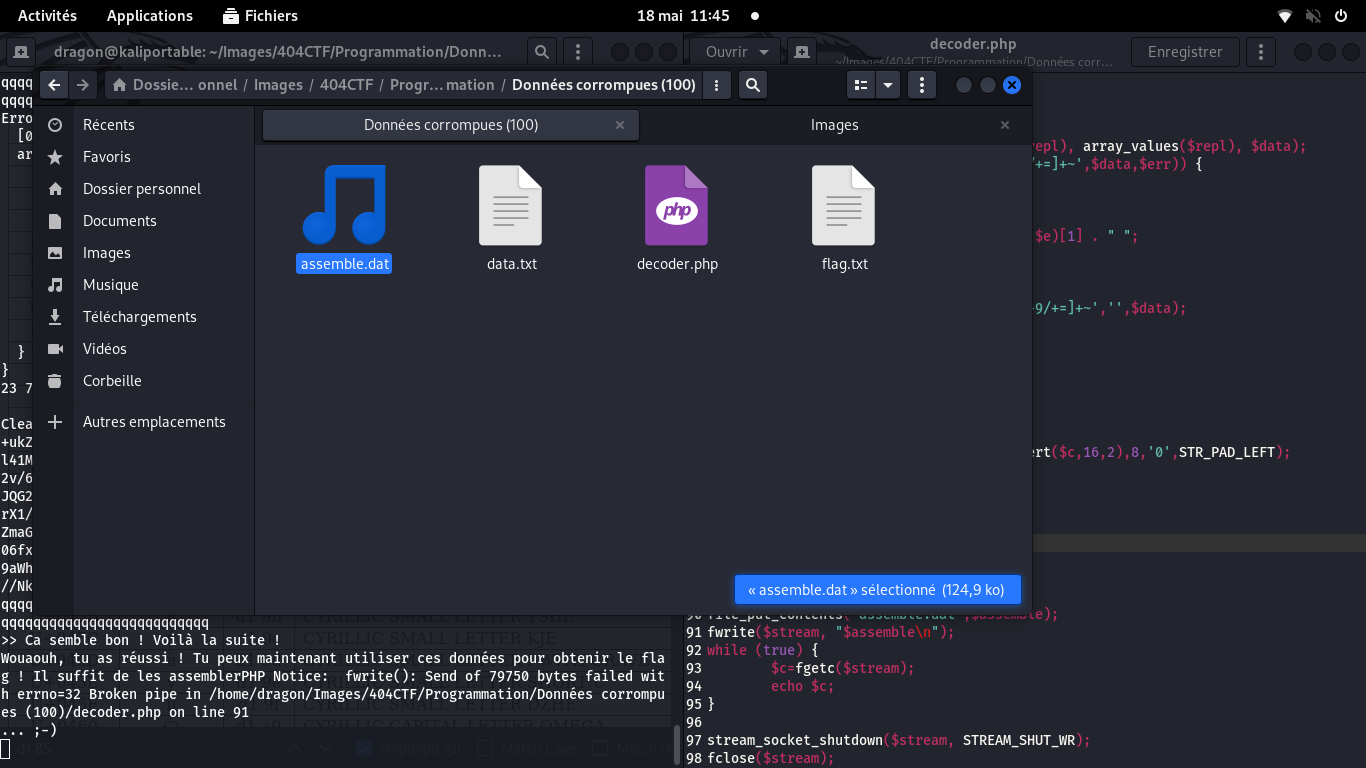
je le relance et j'obtiens un fichier audio
En pratique, c'est un "fichier de données" pour moi, car j'ignore ce qu'il contient, mais
Linux (nautilus) l'identifie immédiatement comme un fichier audio (la commande file le ferait aussi)
Ce fichier audio nous dicte le flag:
404CTF{l4_b4s3_64_3ff1c4c3_m41s_c4pr1c13us3}
 Principe:
Principe: