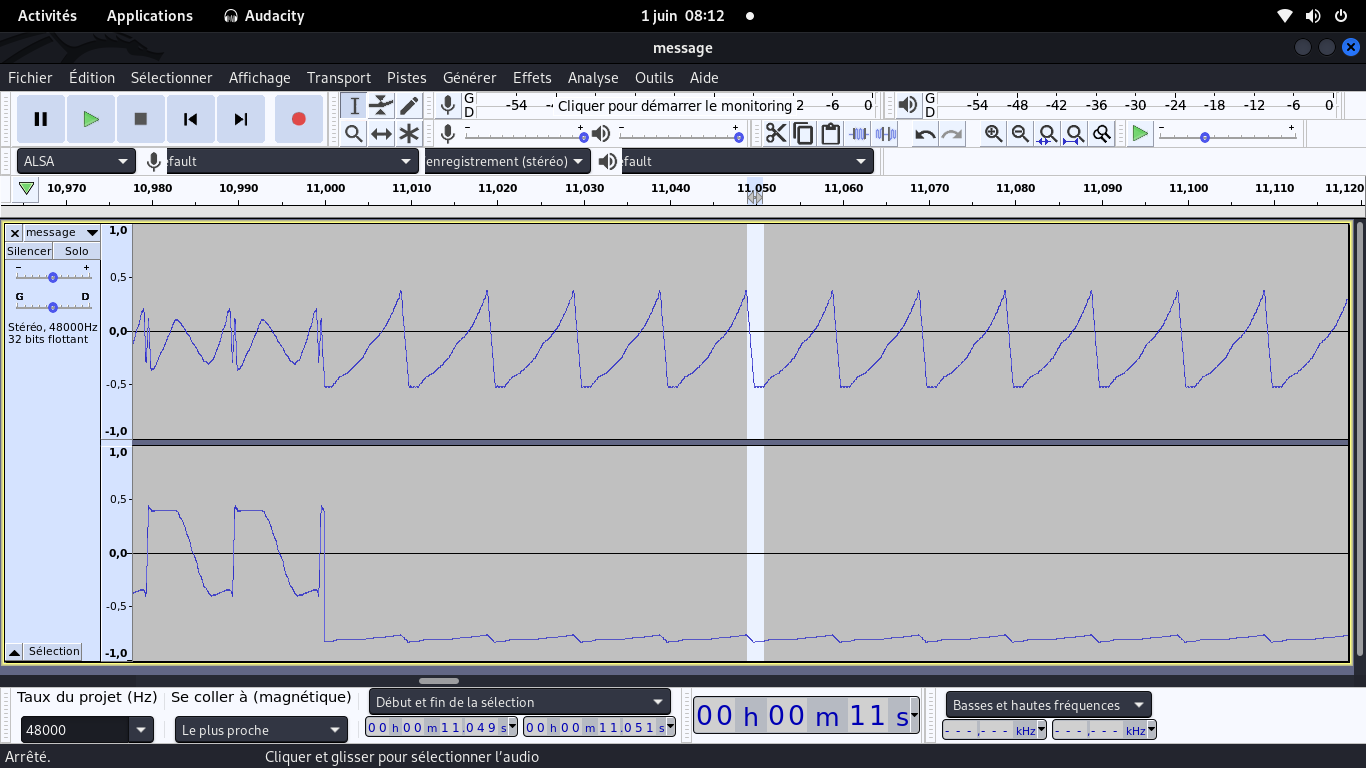
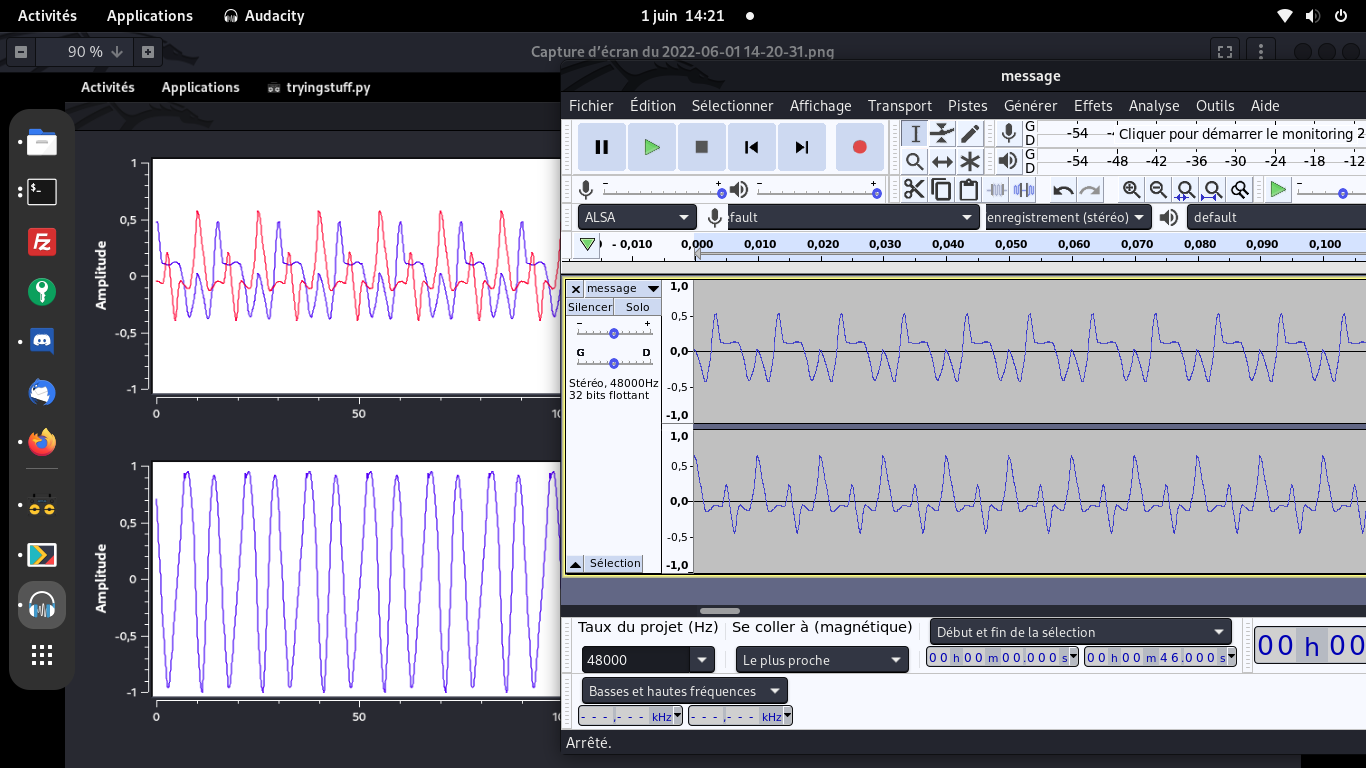
En ouvrant le fichier audio dans Audacity, on s'aperçoit qu'il s'agit de "bruits" successifs
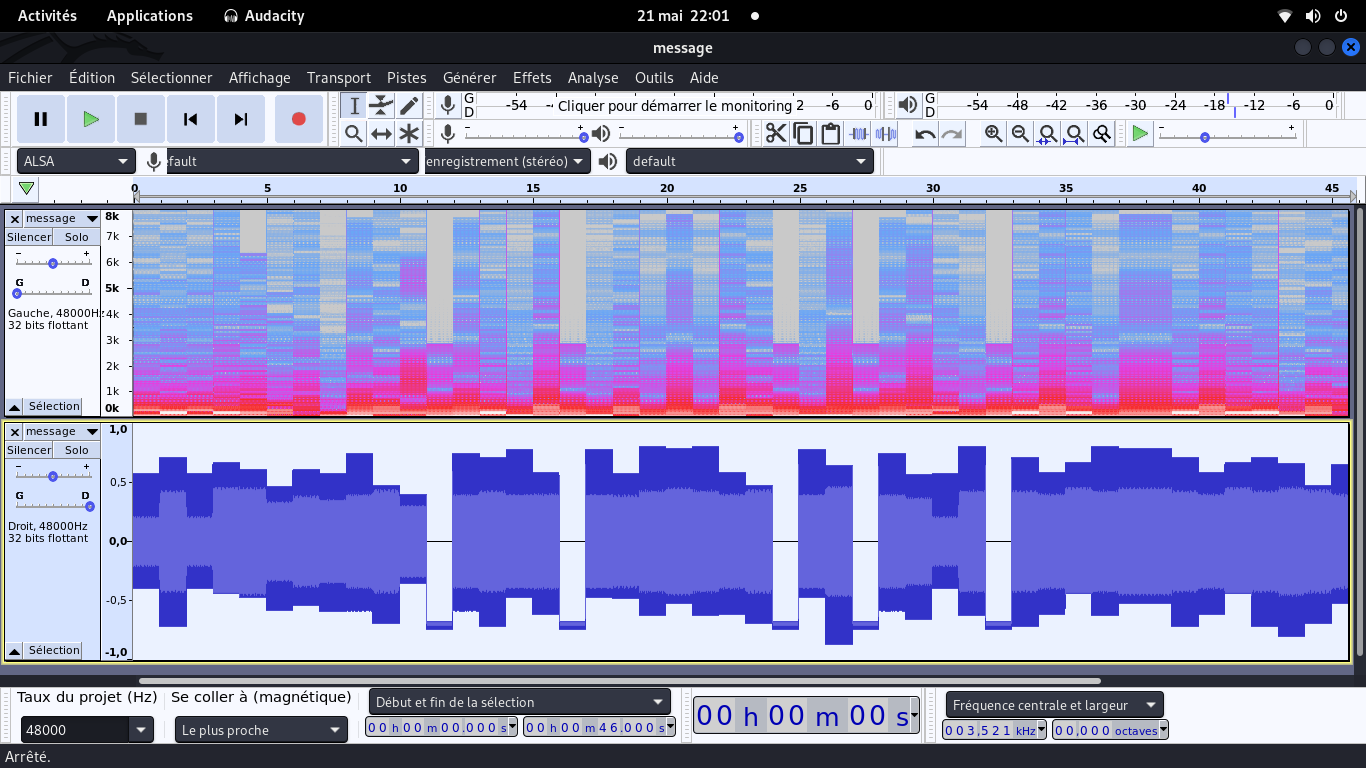
Avec un clic droit sur un canal audio, vous pouvez passer du diagramme d'échantillons
(en bas, en bleus) au spectrogramme de fréquences (en haut, en rouge-bleu).
Parfois, l'un sera plus intéressant que l'autre
Au vu de l'audiogramme du bas, il me semblait certain que 1 bruit = 1 lettre.
Cela se confirme car le 3e bruit et le premier sont identiques,
ce qui correspond bien aux 4 dans le pattern 404CTF{…}.
Il se peut aussi que les bruits "très en bas" sur l'audiogramme soient les underscore,
souvent un peu "spéciaux" par rapport aux caractères alphanumériques
Partant de l'idée que le flag début par 404 soit 41 48 41 dans la table ASCII,
j'ai cherché une logique, mais… rien (à cette échelle)
Décoder l'audiogramme
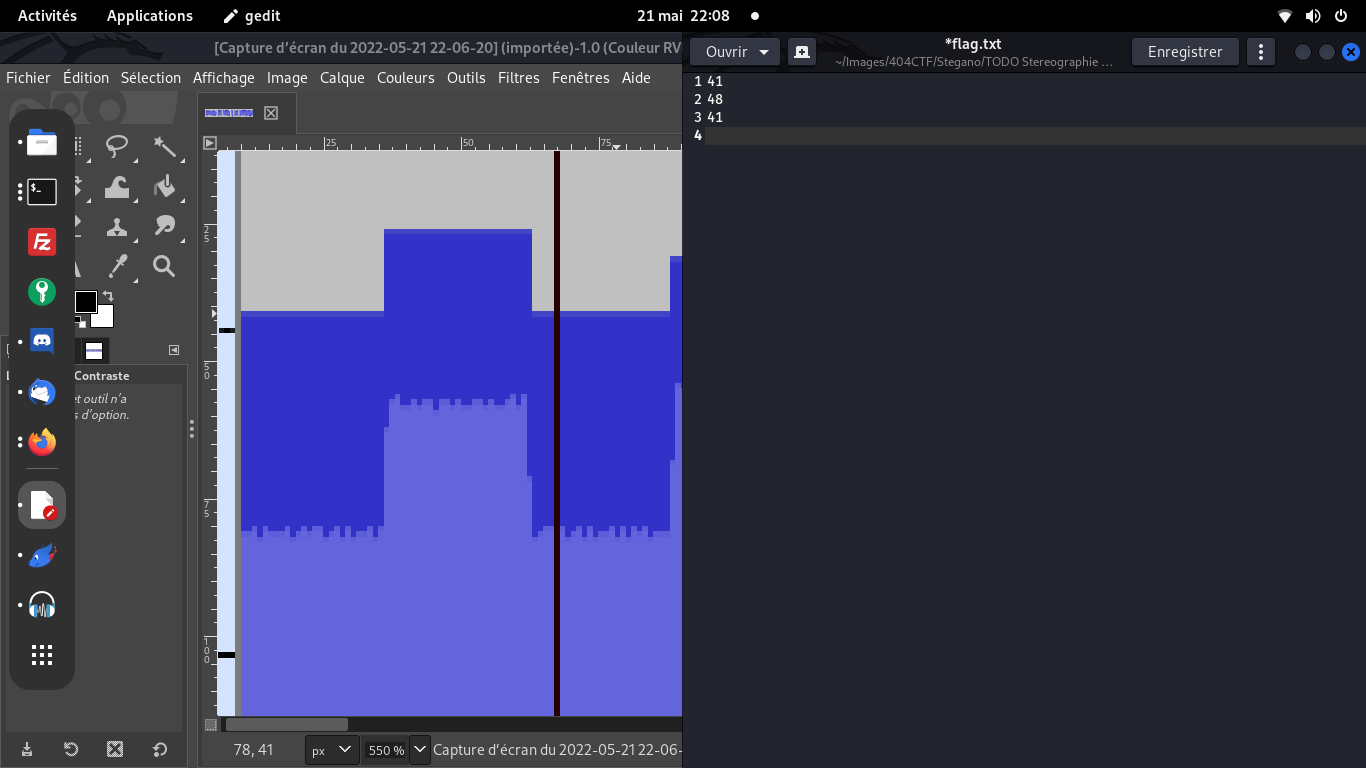
J'ai alors screenshoté (parce que simple!) l'audiogramme d'Audacity,
et j'ai tenté de faire un script PHP pour repérer quels bruits sont identiques
Mon but était alors de décoder le flag comme un chiffrement par substitution,
et d'en tirer peut-être un indice pour résoudre réellement le challenge :)
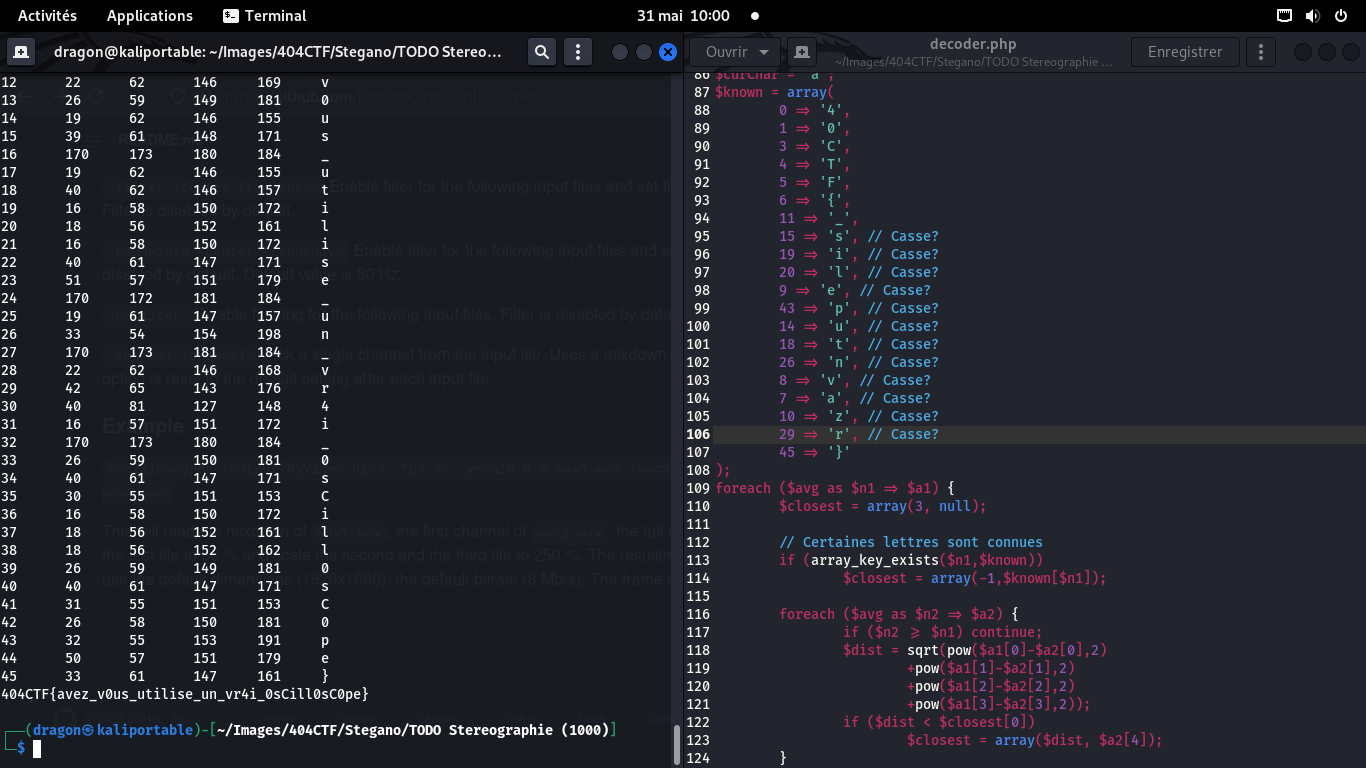
Le script m'a alors sorti des valeurs
(i-eme bruit Y-haut-bleu-sombre Y-haut-violacé Y-bas-violacé Y-bas-bleu)
que j'ai mappé à des lettres (connues ou non)
Ma méthode de mesure était imprécise: les bruits 0 et 2, théoriquement identiques
car représentant un 4, n'avaient pas les mêmes valeurs:
l'égalité doit donc être "floue" (approximative) pour que la méthode marche
En rajoutant du "flou" aux égalités et en forçant certaines lettres du pattern,
on arrive à un résultat plutôt "fiable"
En dehors du C et du 0, les autres lettres ont été choisies au hasard.
Le fait que le dernier mot finisse en C0pe est juste un coup de chance
Trouver les mots
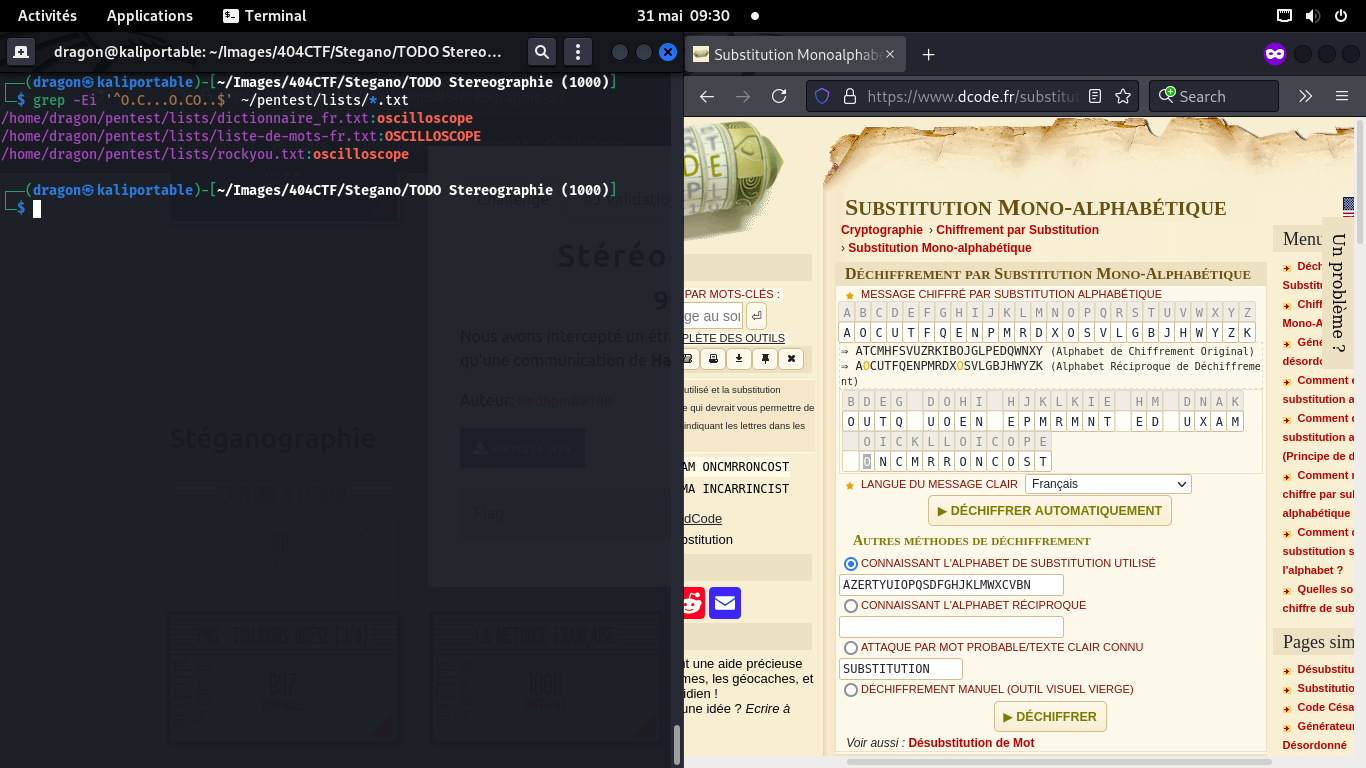
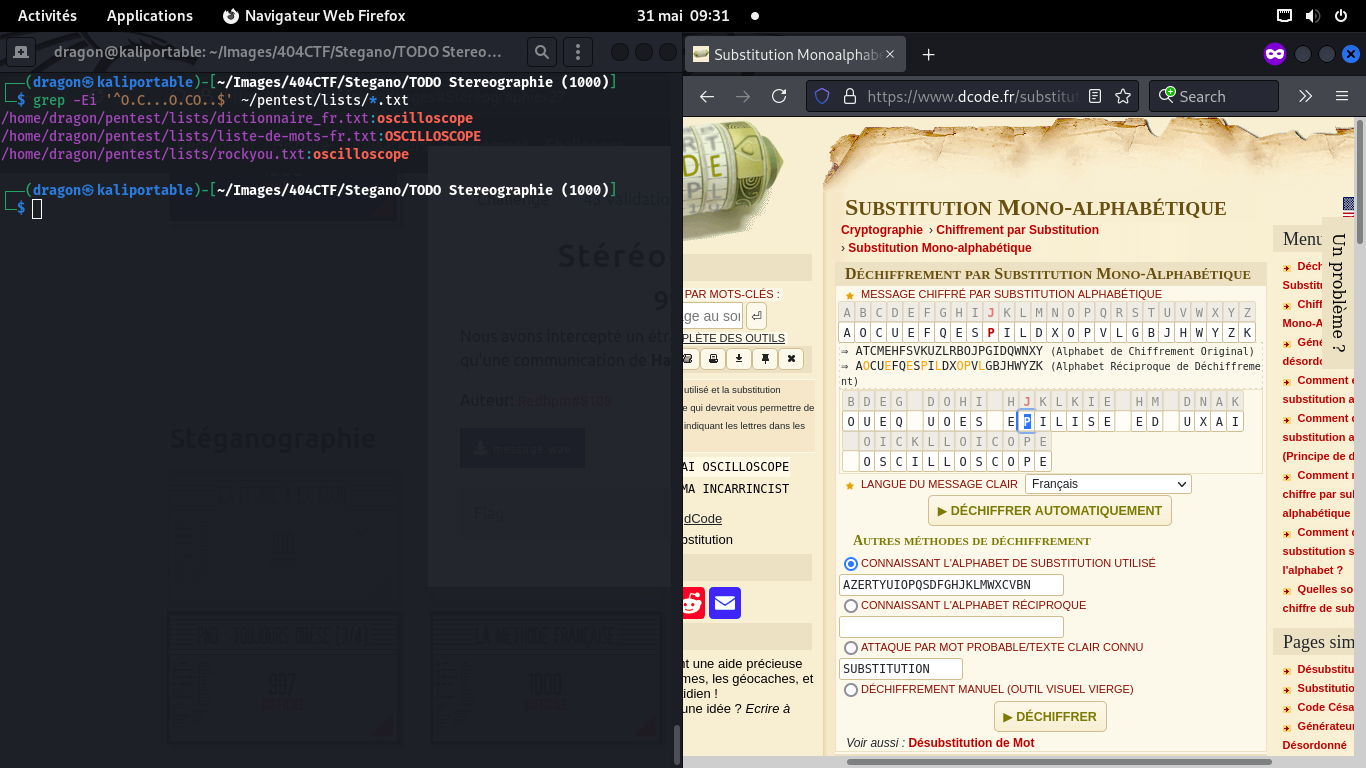
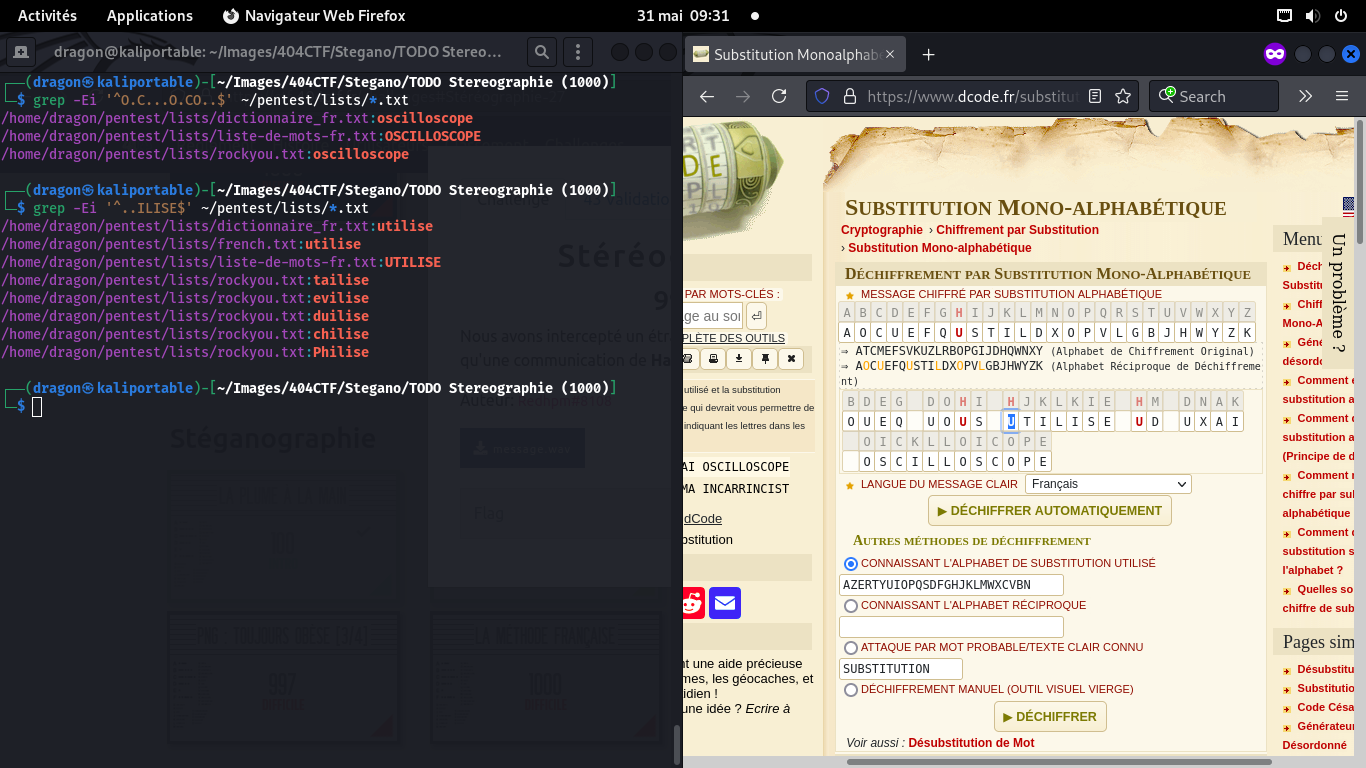
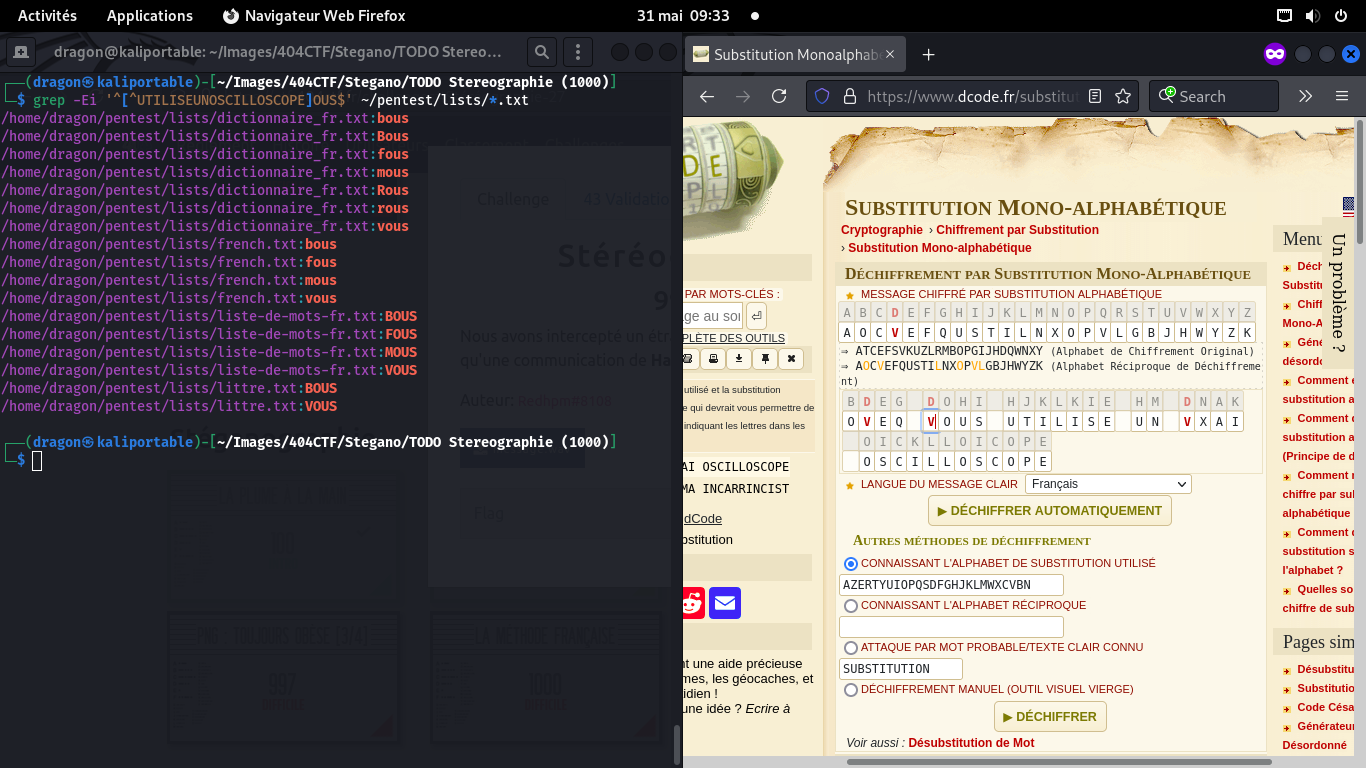
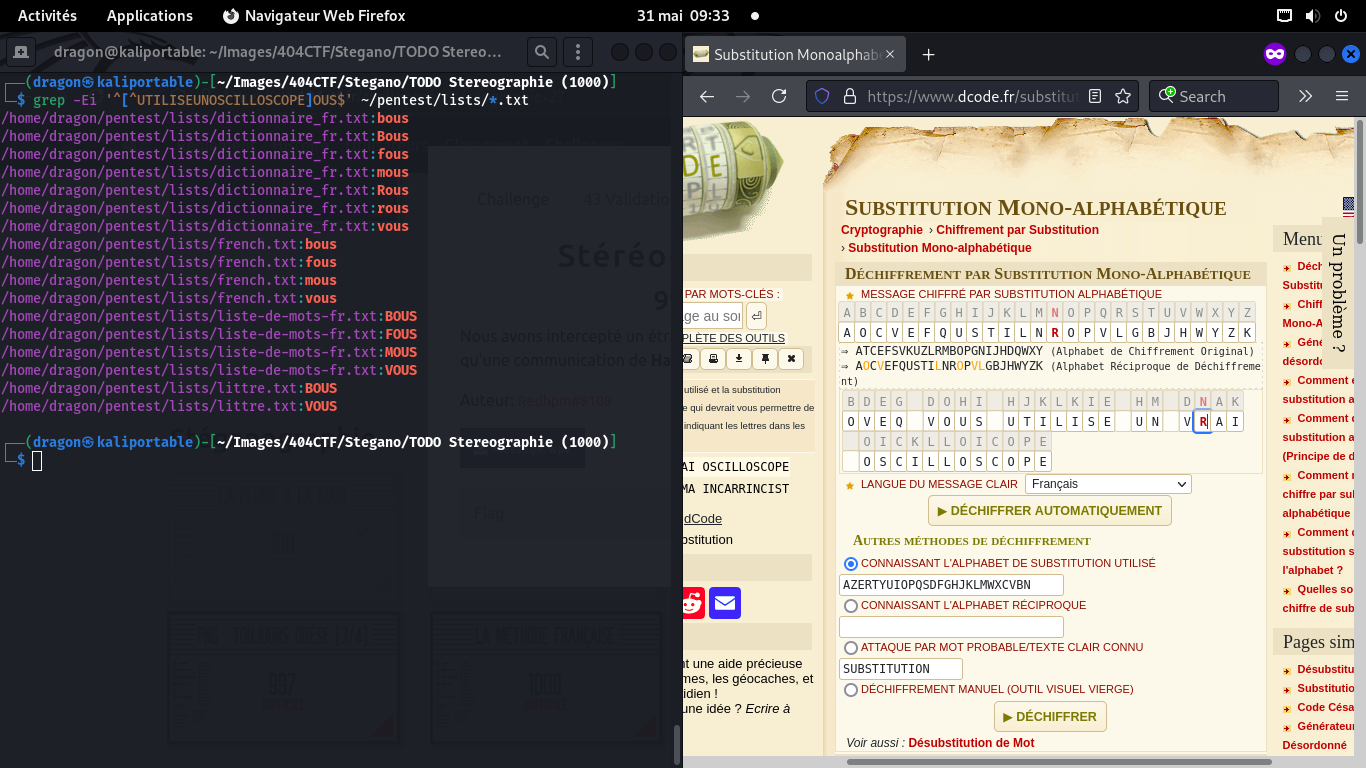
On cherche alors, dans dcode, si le flag peut faire sens,
mais il est encore trop incertain
On a quand même de la chance: le 0 se retrouve à plusieurs endroits,
donc, on sait que plusieurs lettres sont des O. De même, le 4 dans le flag est
certainement un A
Le dernier mot semble assez long, et spécifique: en cherchant dans mon dictionnaire,
seul un mot correspond, et il a une lettre doublée qui correspondrait bien
au "bruit plus long" qu'on entend au milieu
Dans dcode, on peut alors forcer le dernier mot à être "Oscilloscope",
qui est par ailleurs bien dans le thème d'un CTF
On infère de même que le mot du milieu doit être "utilise", ou quelque chose du genre
Idem avec le mot précédent, même si "vous utilise", je trouvais ça absurde…
Mais au final, Avez-vous utilisé un vrai oscilloscope, c'est plutôt par mal comme résultat!
On a donc une piste de résolution
On ne peut pas soumettre ce flag "deviné" car il est écrit en l33t et on ignore sa casse.
On va donc devoir résoudre réellement le challenge, et se servir de ce qu'on a trouvé seulement
comme d'un indice
On notera le flag "théorique" de côté, au cas où, pour ne pas le perdre.
Il nous manque maintenant la casse et le l33t
Oscillons
J'ai essayé de voir, via ffmpeg, l'évolution des oscillations de l'audio,
mais cela ne donna rien de concluant (seulement les mêmes courbes qu'audacity, ce qui est logique)
En reprenant Audacity, je me suis intéressé à la façon dont les courbes oscillent,
mais je n'ai rien vu d'évident
J'ai aussi cherché une astuce dans GNU Radio (une addition? multiplication? des signaux)
mais rien là non plus
Ou peut-être un déphasage? non plus…
On notera que GNU radio et Audacity montre quasiment les mêmes courbes, ce qui est rassurant
En faisant le ménage, une idée m'est venue: le titre est
"Stéréographie",
c'est à dire utiliser deux images 2D pour rajouter une dimension 3D.
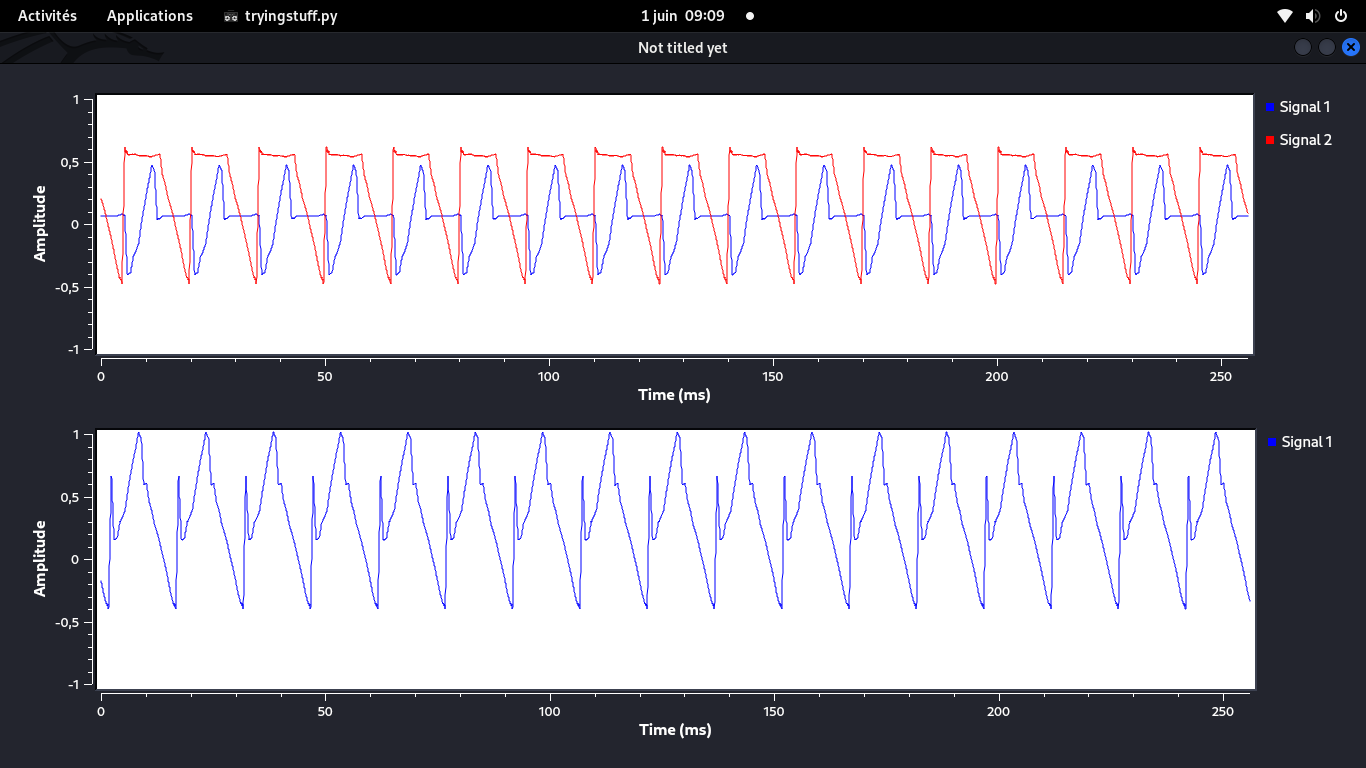
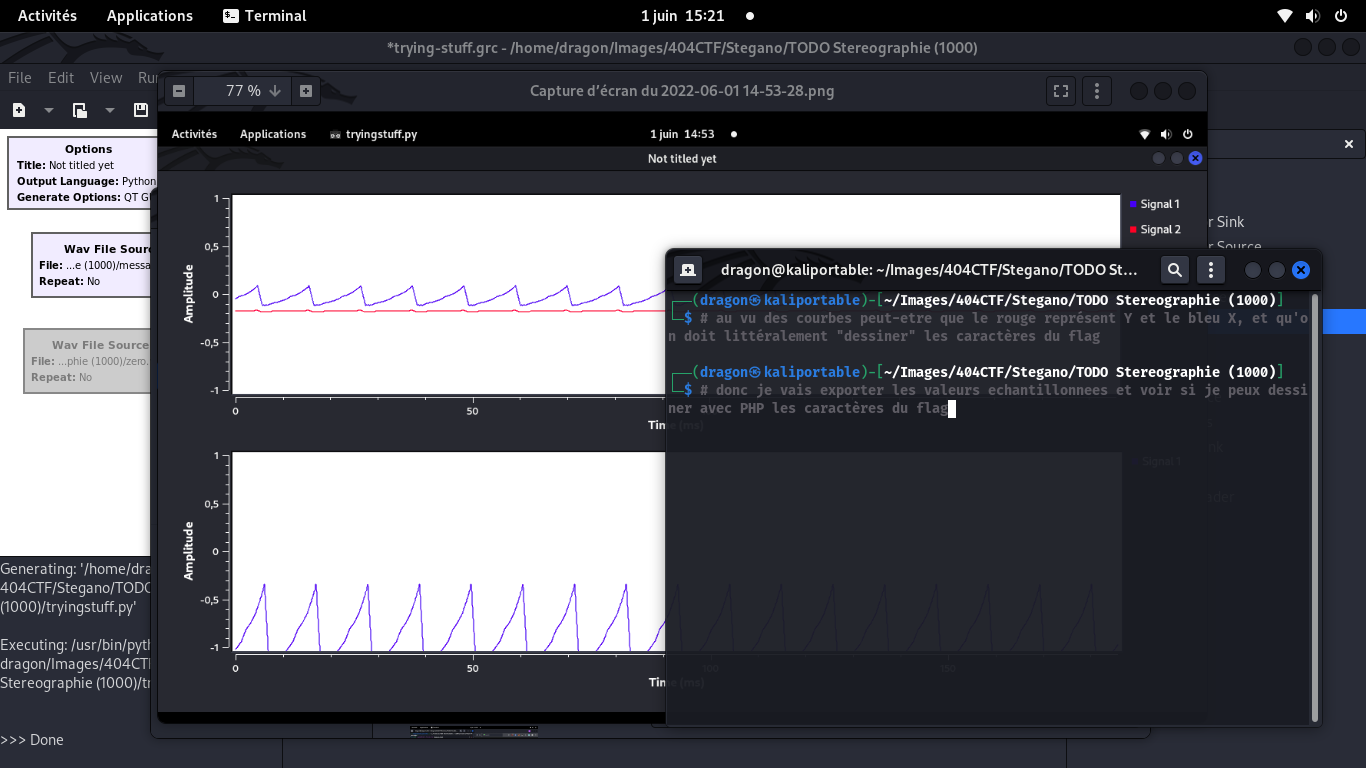
Peut-être que les courbes 1D stéréo s'assemblent pour donner une image 2D?
Ayant la courbe précédente en tête, je m'étais dit "cette idée marcherait surement bien,
car les underscores sont représentés par une courbe (rouge) quasi plate et une courbe (bleue)
qui monte un peu, ce qui dessinerait bien un trait plat si la courbe rouge est Y et la bleue X
Traçons
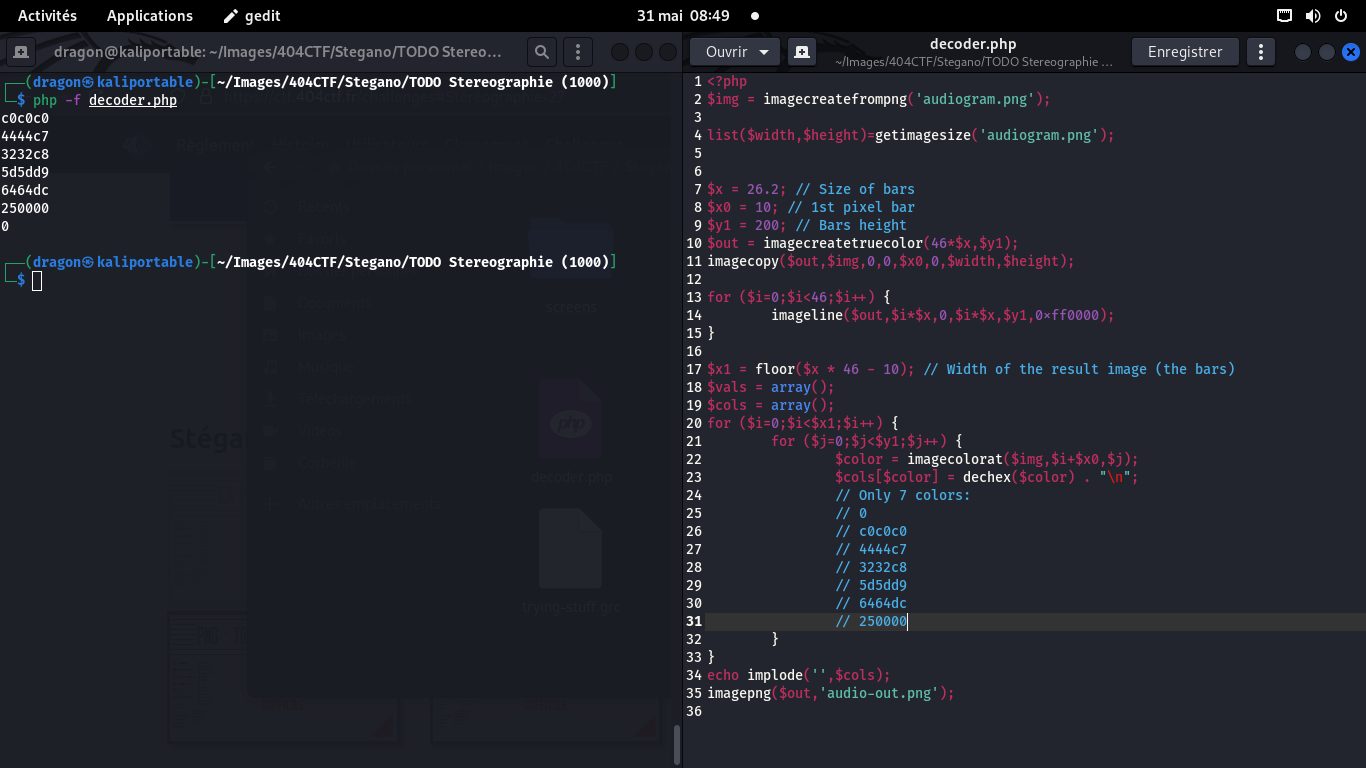
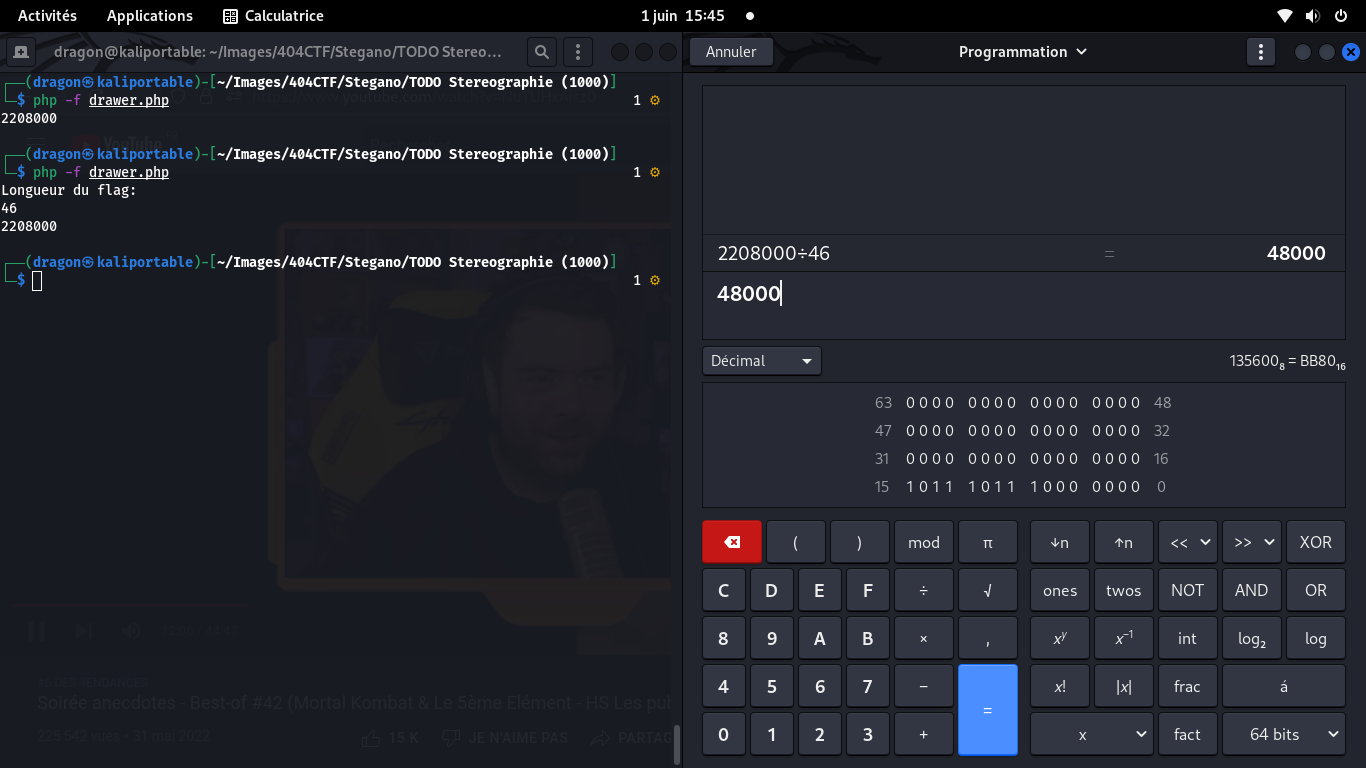
Via GNU radio, j'ai donc sorti un fichier de données listant les valeurs échantillonnées
de chaque canal audio (gauche et droite). Le format est une simple liste de nombres flottants 32 bits
Je crée mon script, et je le lance pour les premières valeurs exportées par GNU radio:
on lit un 4 !
Comme GNU Radio a exporté toutes les données, j'ai 2208000 échantillons, pour 46 caractères.
Je cherche donc combien d'échantillons seront à lire pour chaque caractère
Notez que, ayant 48000 échantillons par lettre, si on écoute l'audio avec une fréquence d'échantillonnage
de 48kHz, alors chaque lettre durera 1 seconde exactement
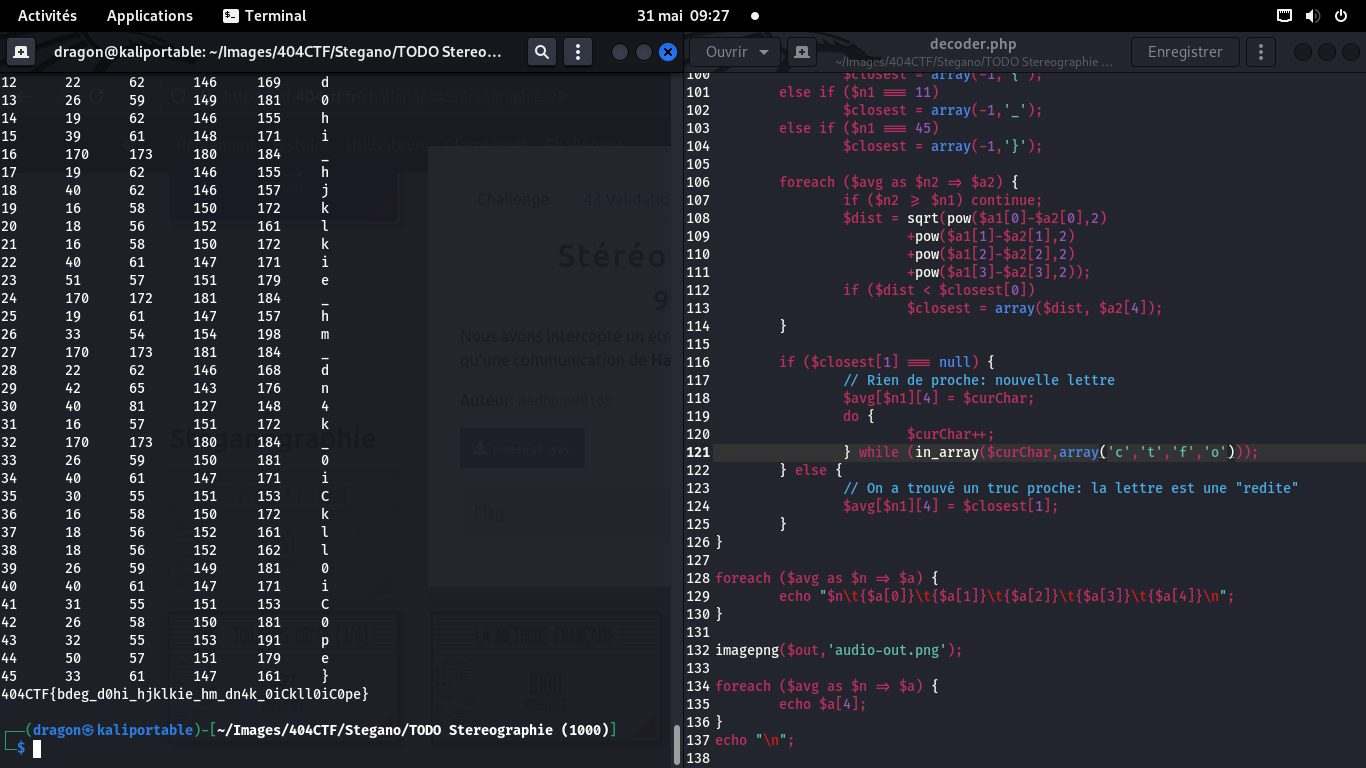
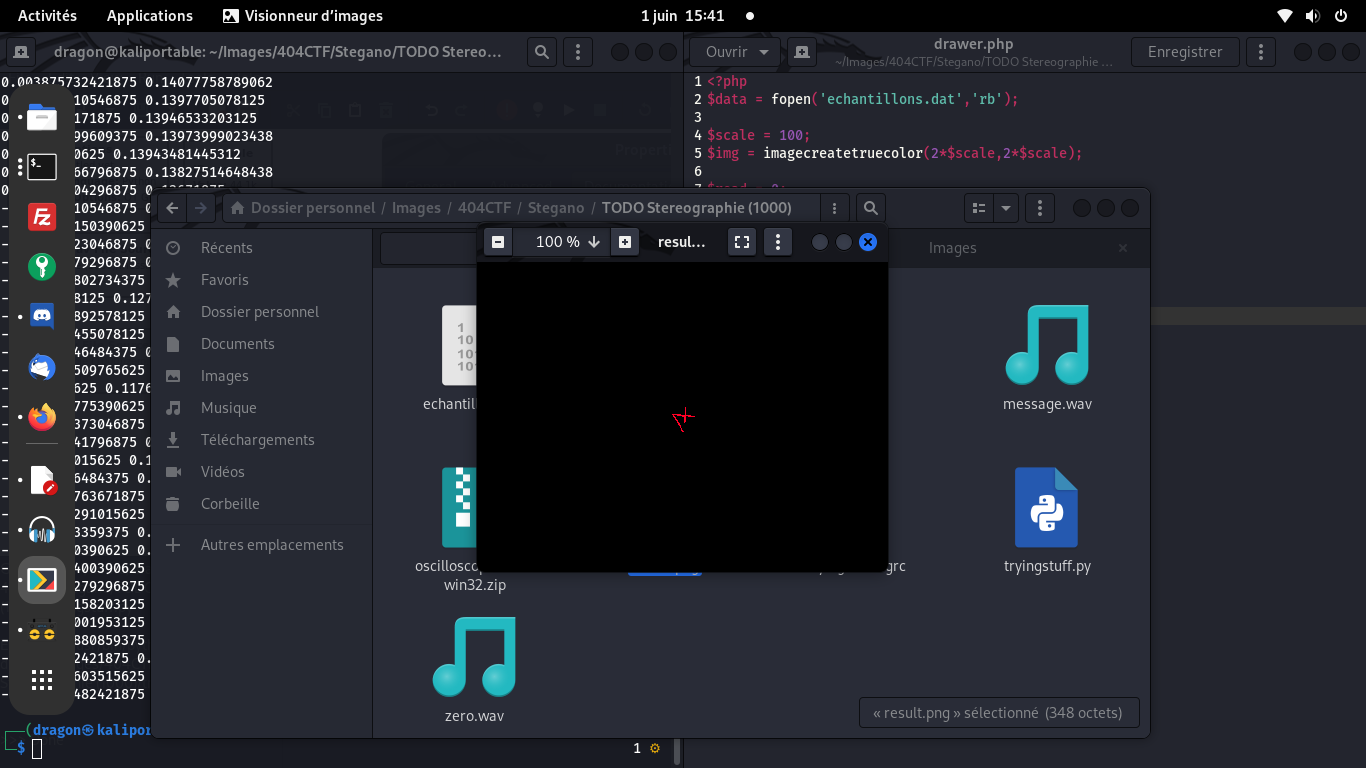
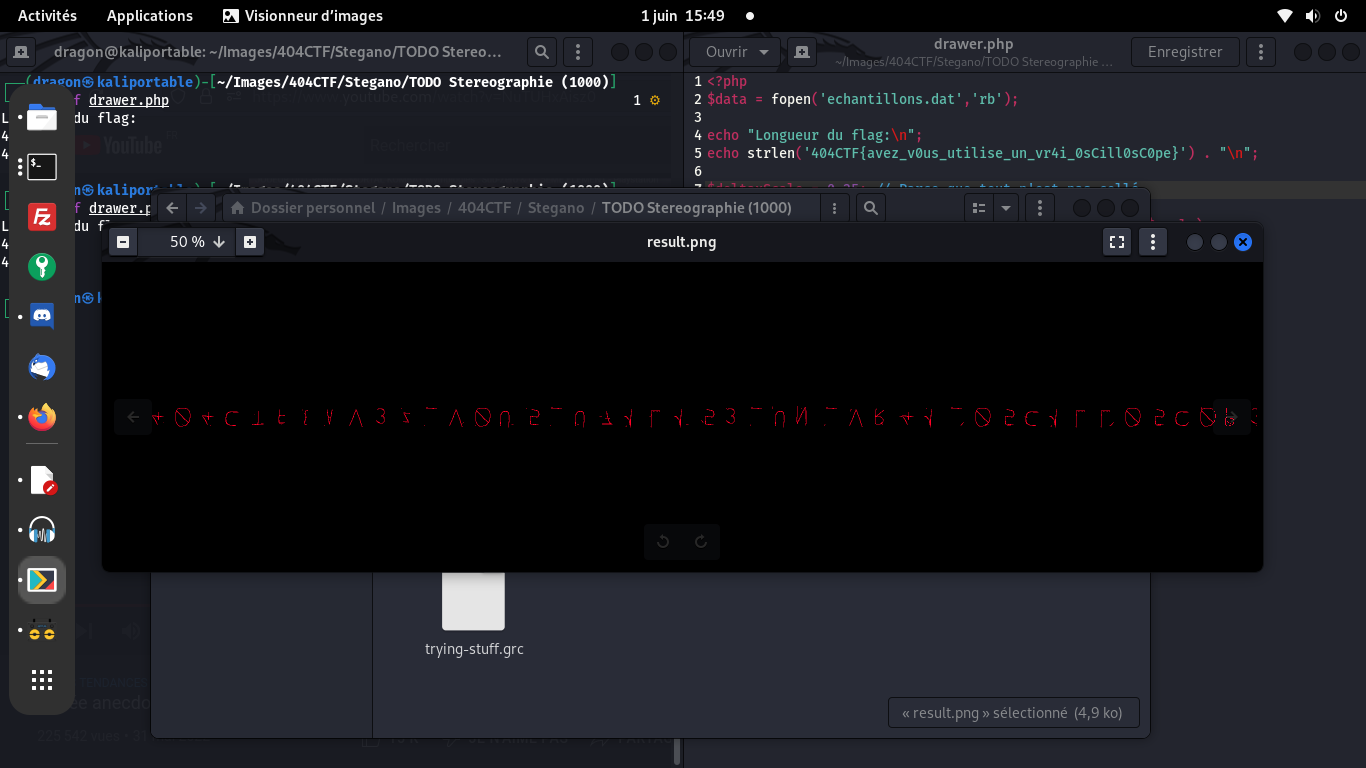
On trace alors le flag complet, lettre à lettre, et on le sauve dans une image
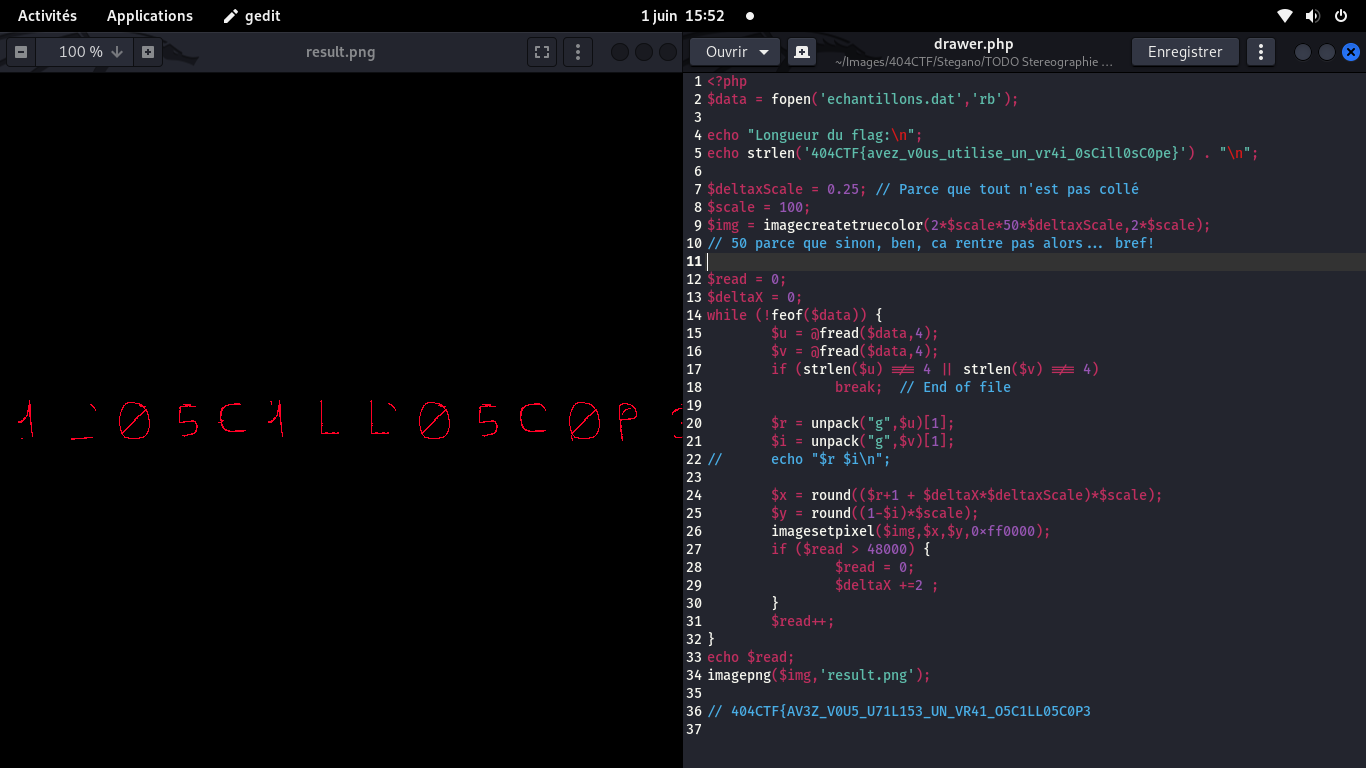
On remet l'image dans le bon sens, on ignore les petits bouts d'artefact, et on a le flag:
404CTF{AV3Z_V0U5_U71L153_UN_VR41_05C1LL05C0P3}
La joie quand on flag le dernier challenge "Facile"
 Principe:
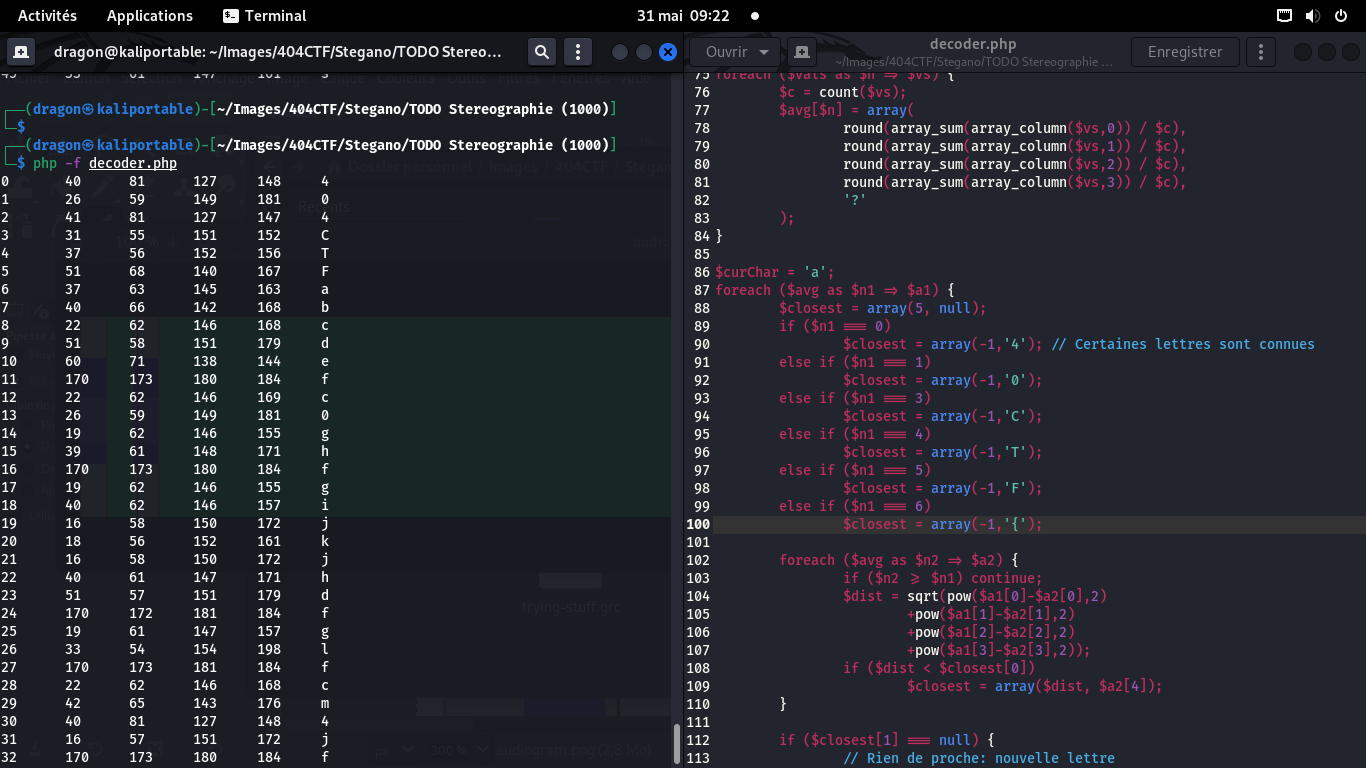
Principe: