Data destruction is a critical part of a DLP. I was told that
wear leveling
made the shred command useless.
So let's check.
Setup
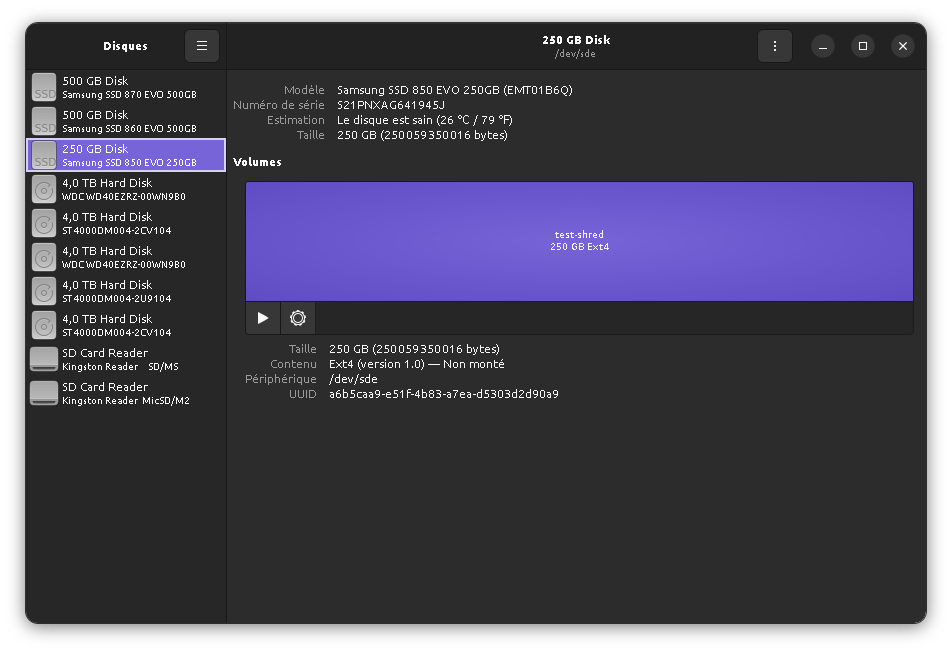
We'll check the data destruction process using a simple setup: a Samsung 850 EVO SSD (128GB) data disk (not the disk OS is installed on) that is full of zeroes, formatted in ext4, and that contains a single file with clearly identifiable data. We will then try to delete this file and see how the data (on the disk as a block device ) are erased.
Format (zeroing)
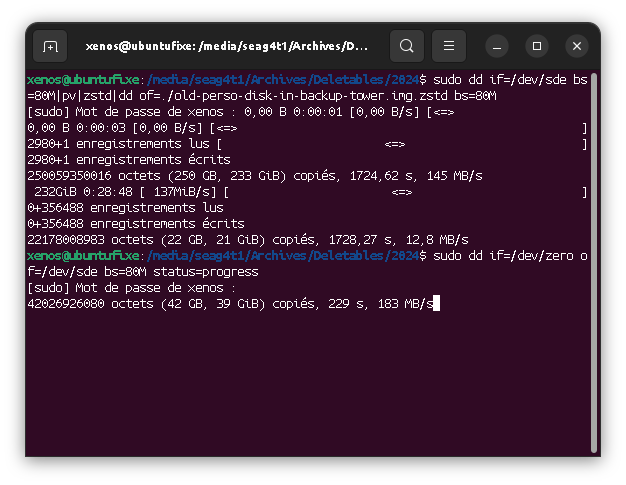
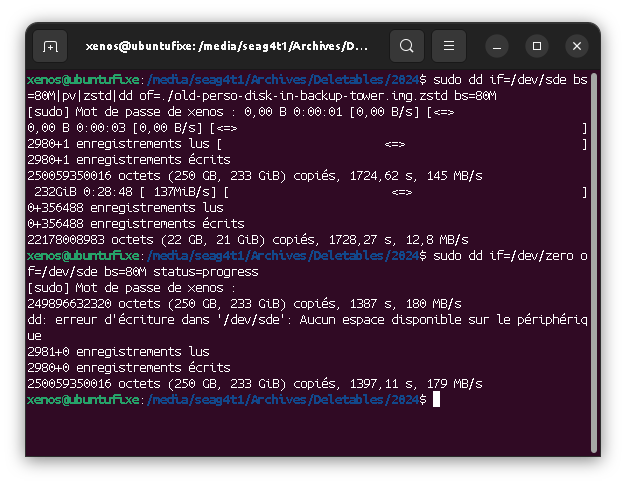
Create a partition
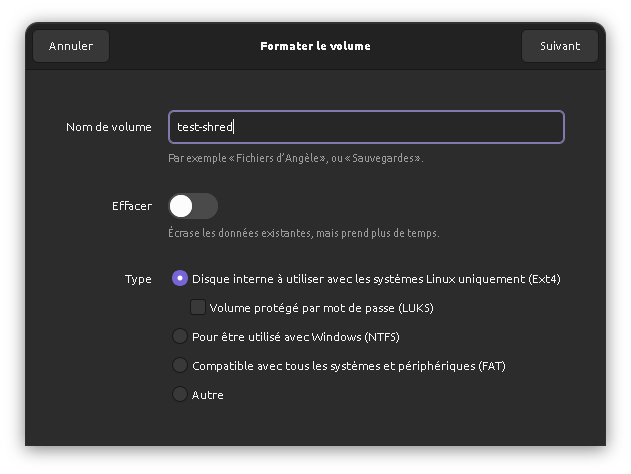
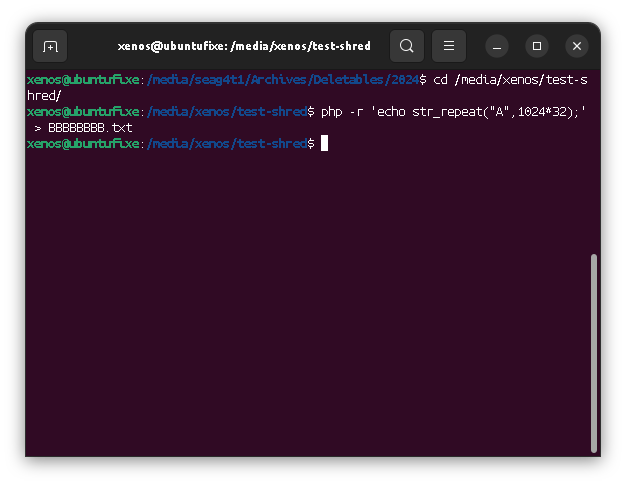
A file with AAAs
Regular file modification
Now that we have a file on disk, let's check what its data (content) life cycle is. We'll check how the disk is storing the file content, and how that storage evolves with the file usage.
How block devices work
Any storage media is seen by the OS as a "block device", that is, a very long stripe of bytes. Bytes are grouped into sectors (512 bytes per sector) and sectors in blocks (8 sectors per block usually, so 4k, but that might be customized to, say, 64k).
So when a file must be stored, its content is split into blocks (here, 4k) and saved on the disk. When saving, each block is subdivided in sector, and each sector is stored contiguously inside each block. But blocks may be spread around on the disk if needed, leading to the so-called "fragmentation".
So for our setup file, we should get a single blocks-range (no fragmentation) of 32k bytes length (because the file has 32k characters), that is 8 blocks of 4k size, each split in 8 sectors of 512b size meaning a total of 64 blocks of 512 bytes.
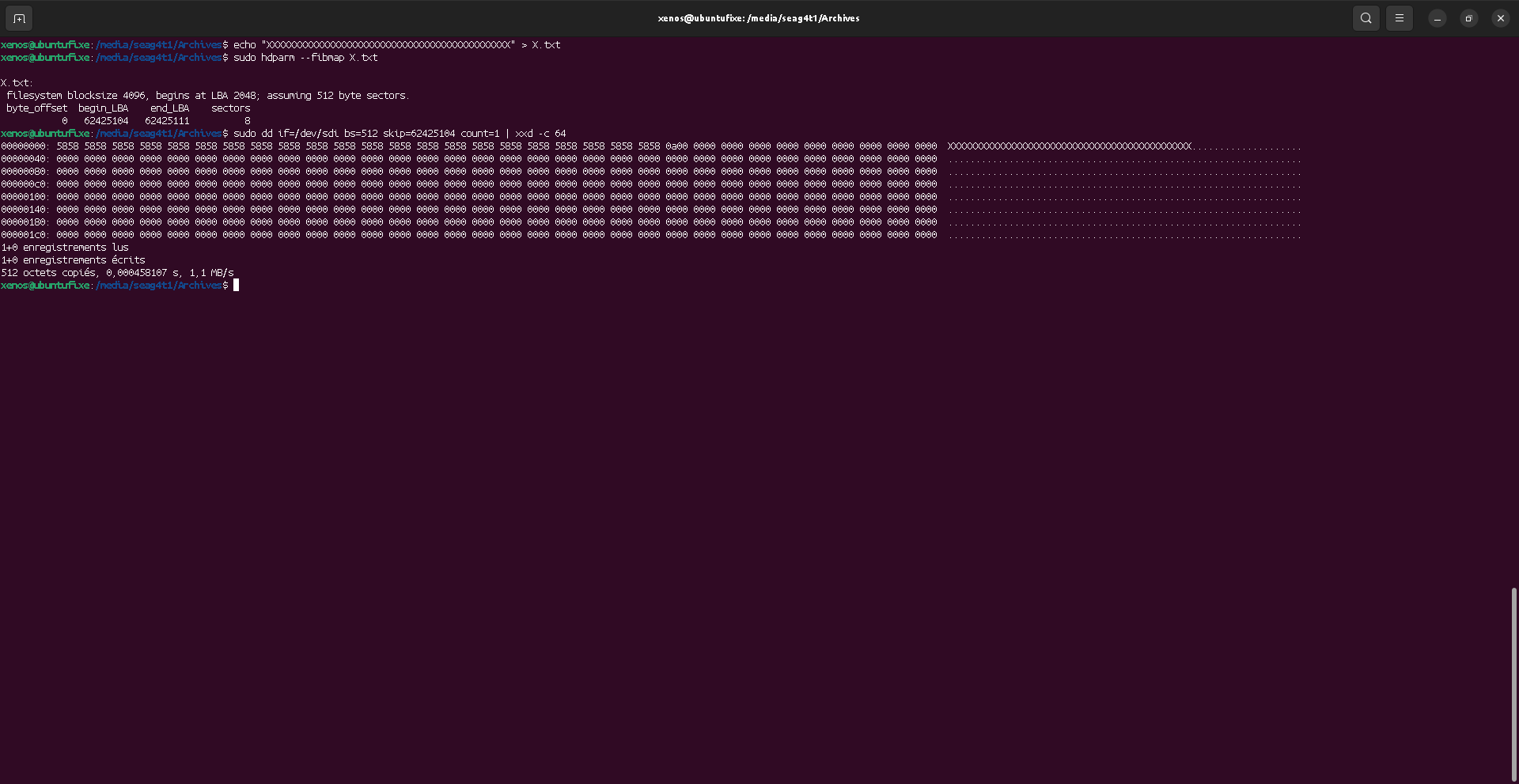
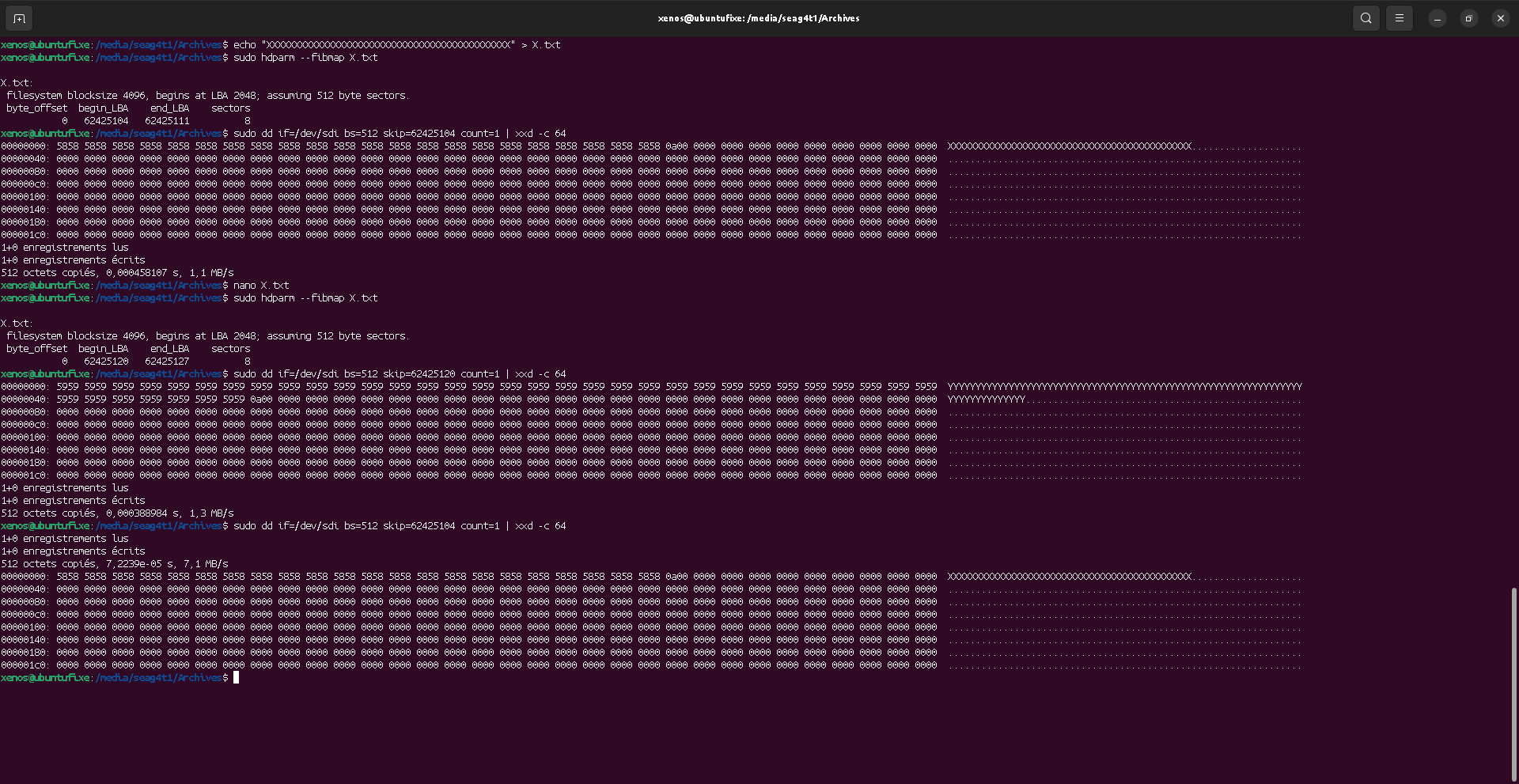
Locate the file content
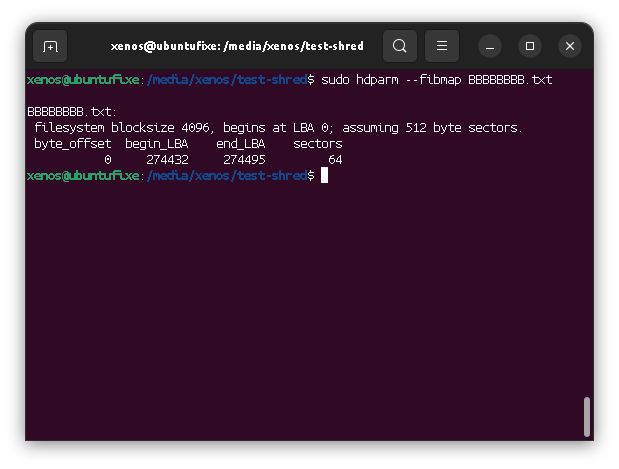
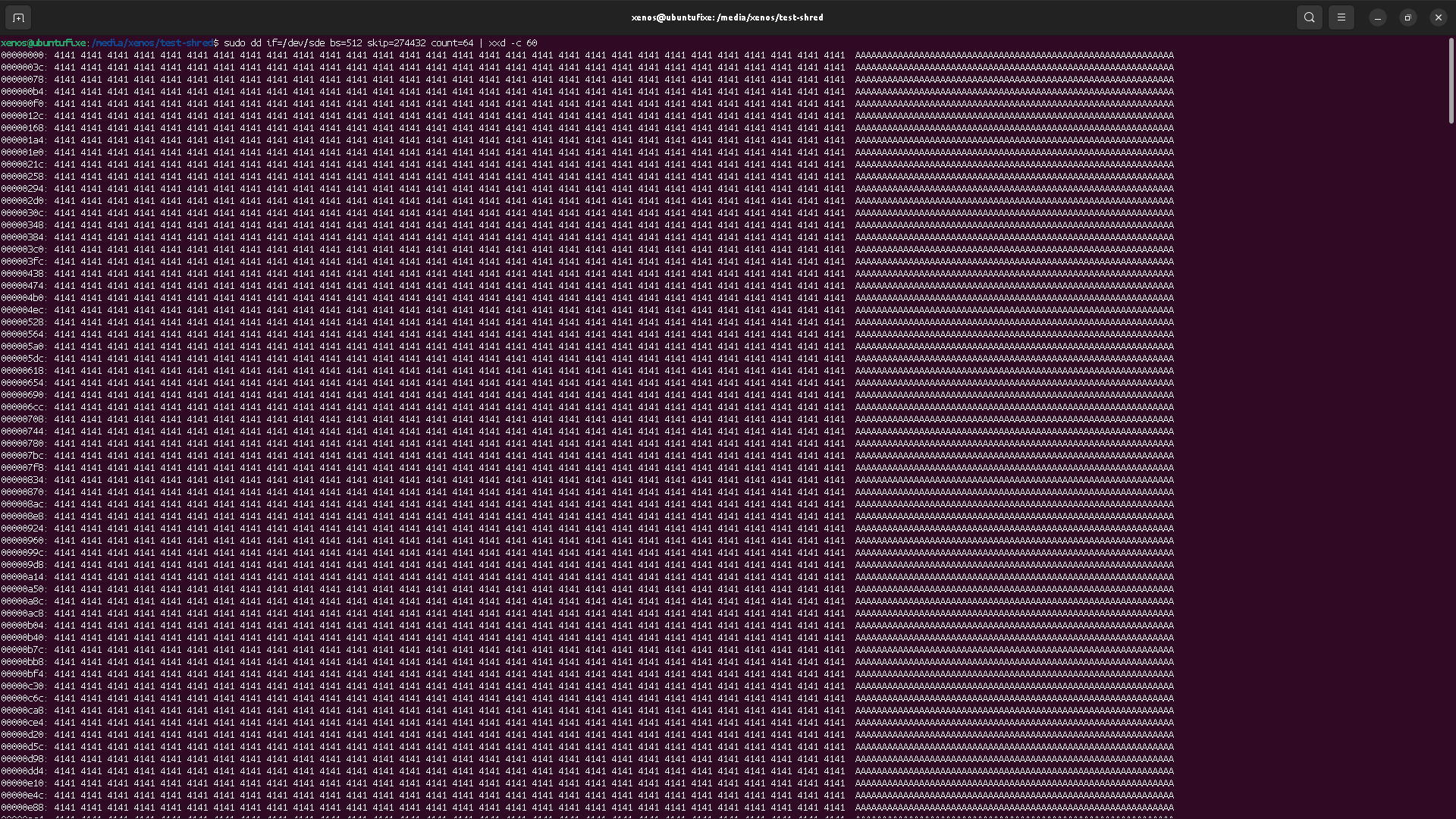
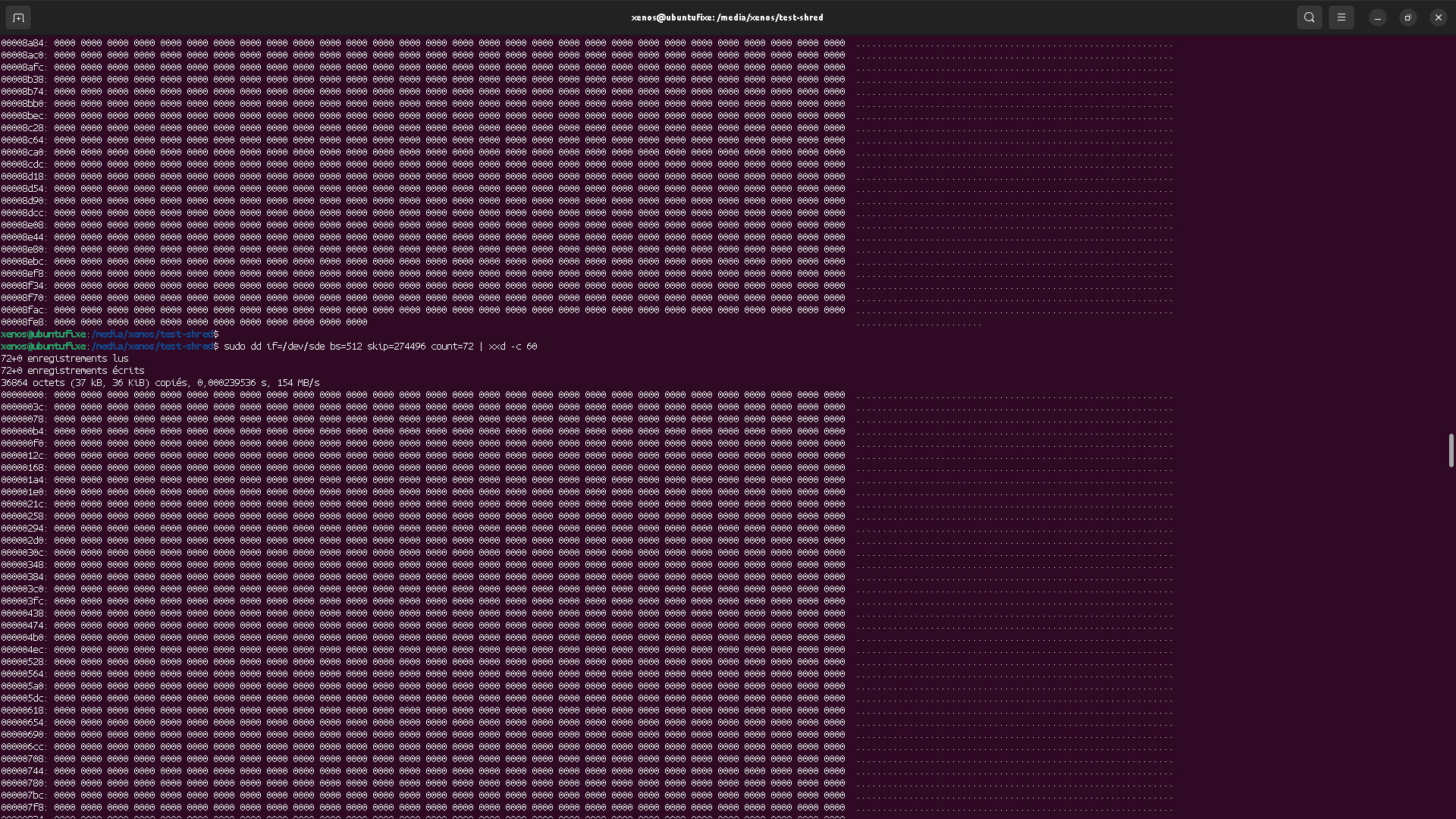
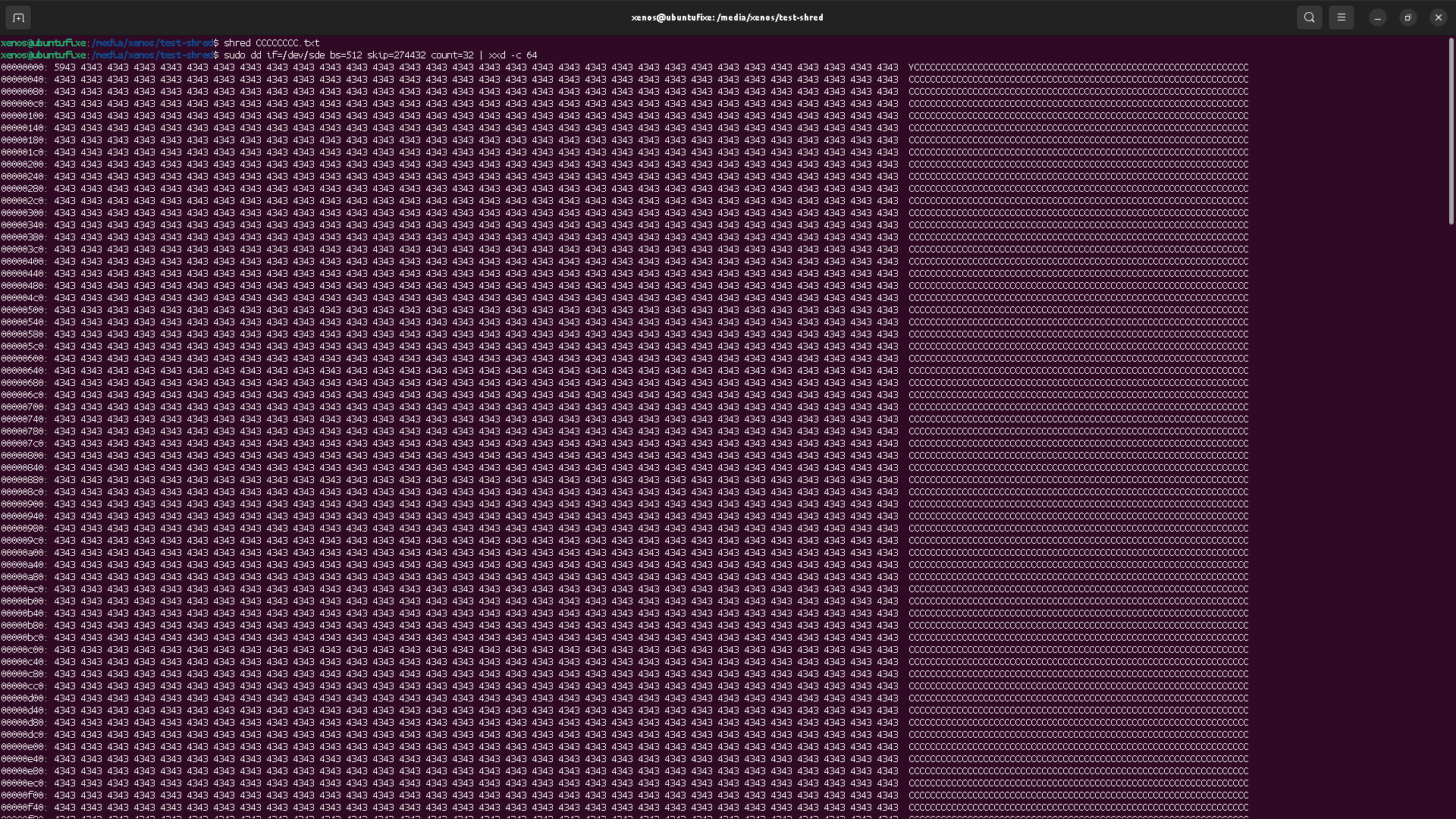
As we can see, file is stored from sector 274432 to sector 274495, meaning it is 64 sectors size with 512 bytes per sector. This matches the expected 32k "A"s of the file content.
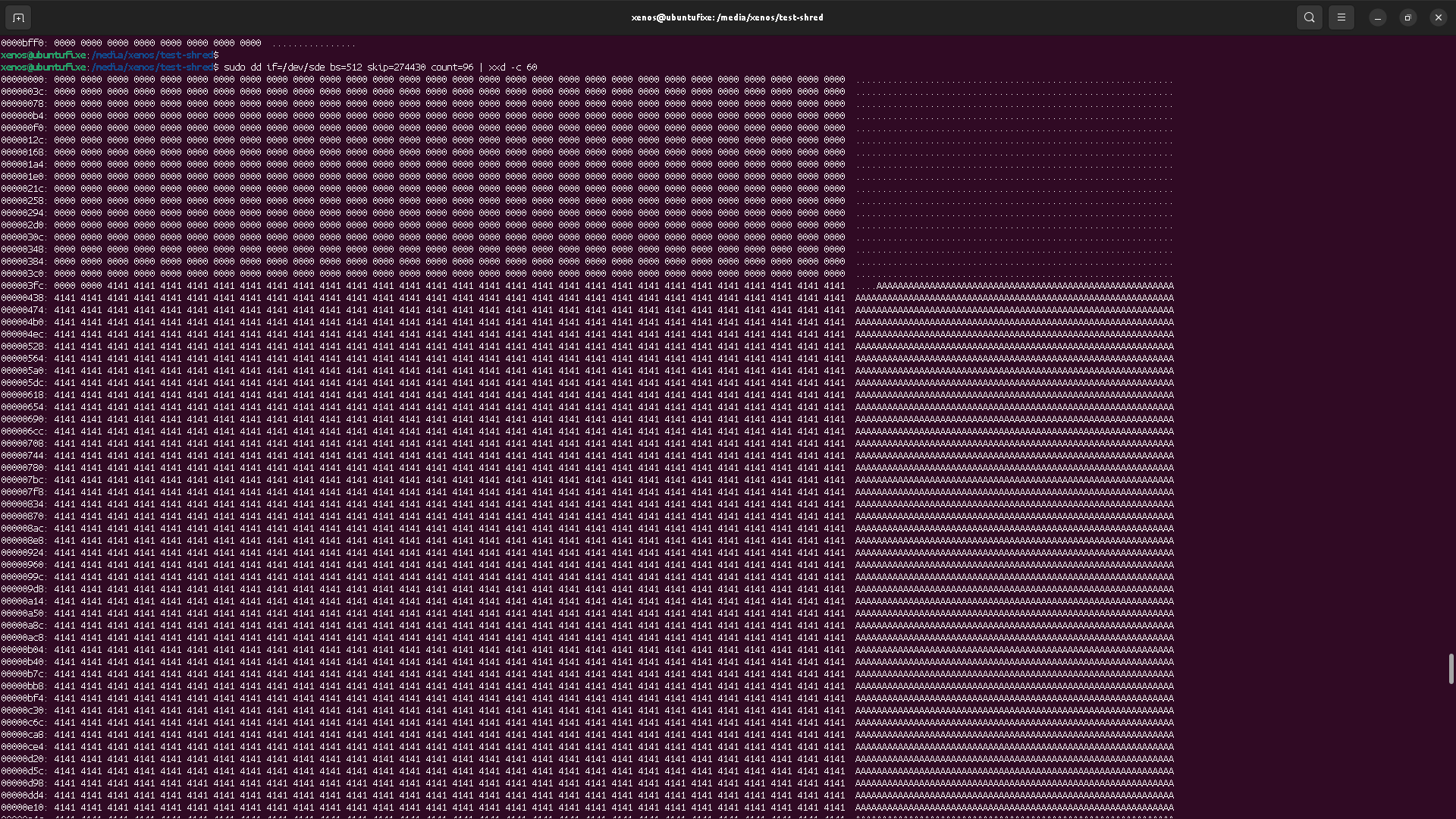
dd will read "blocks" of raw data of the block device.
With bs=512 option, we tell dd to use "blocks" of size 512 (matching the sector size),
so we can skip (ignore) the first 274430 blocks, and see the first sector of file's data.
We could also have done a direct dd if=/dev/sde and then ignored
the first 274432 * 512 = 140509184 characters.
Result would have been the same, but it's uselessly tedious.
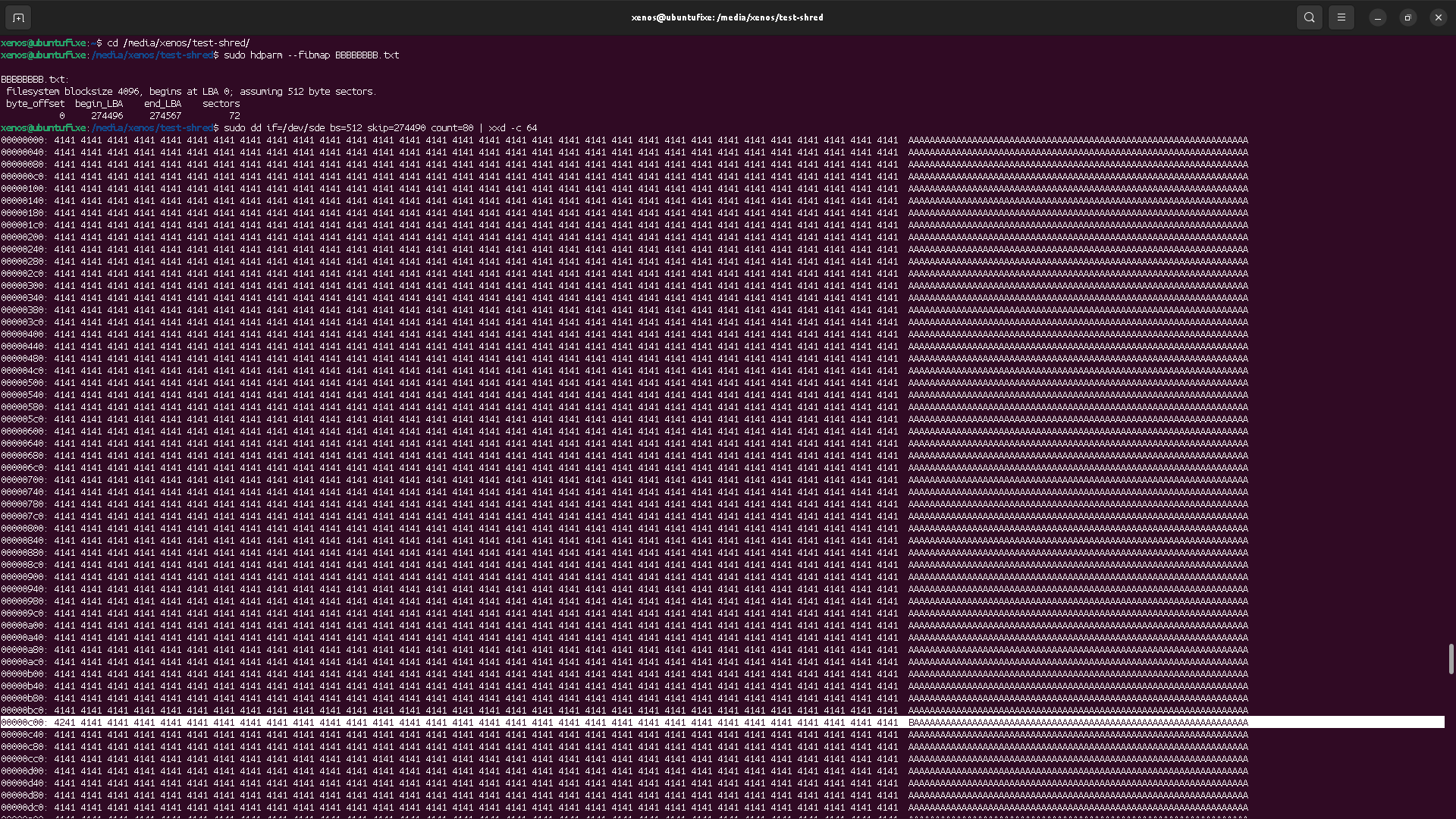
Lifecycle with nano

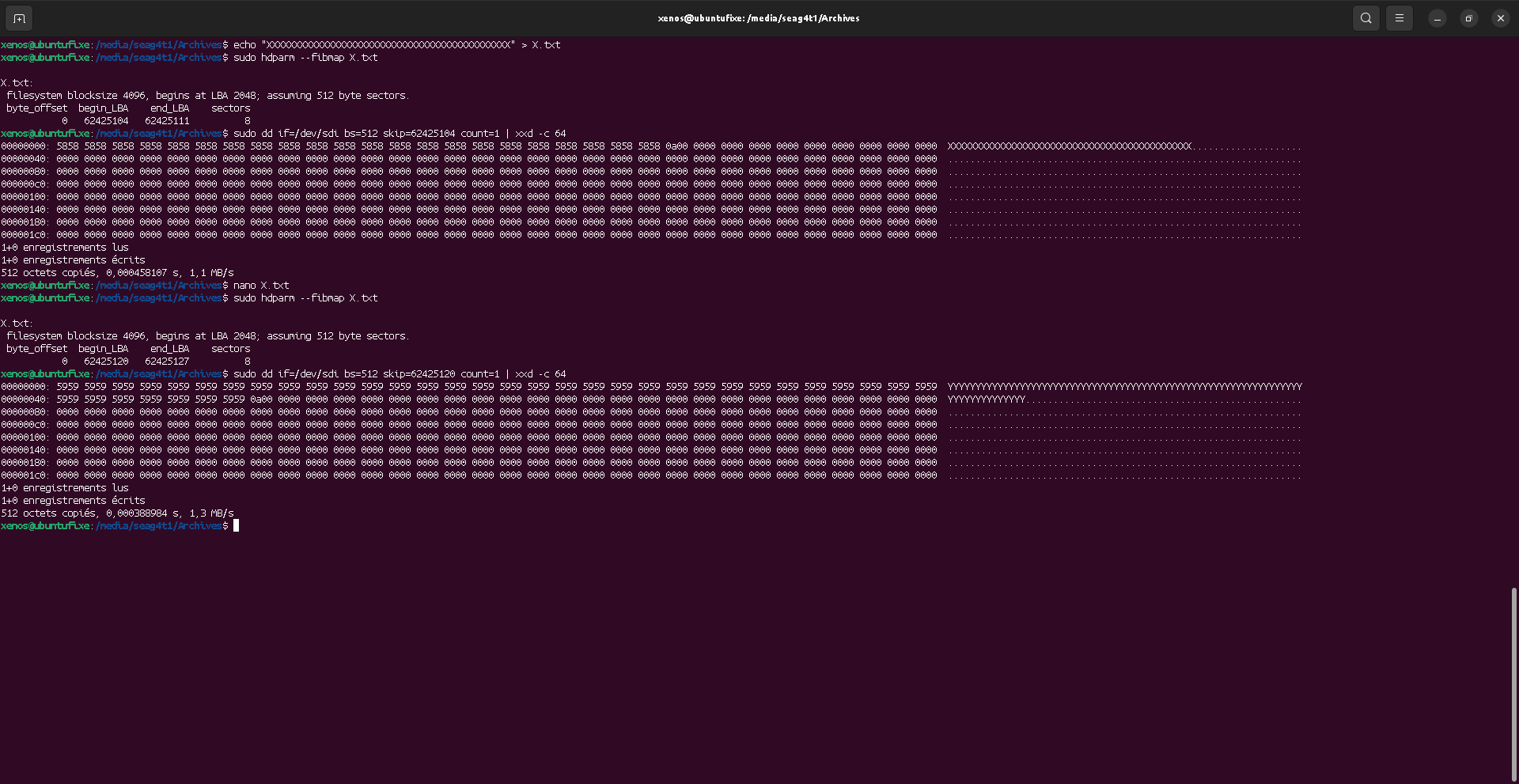
Content location has changed
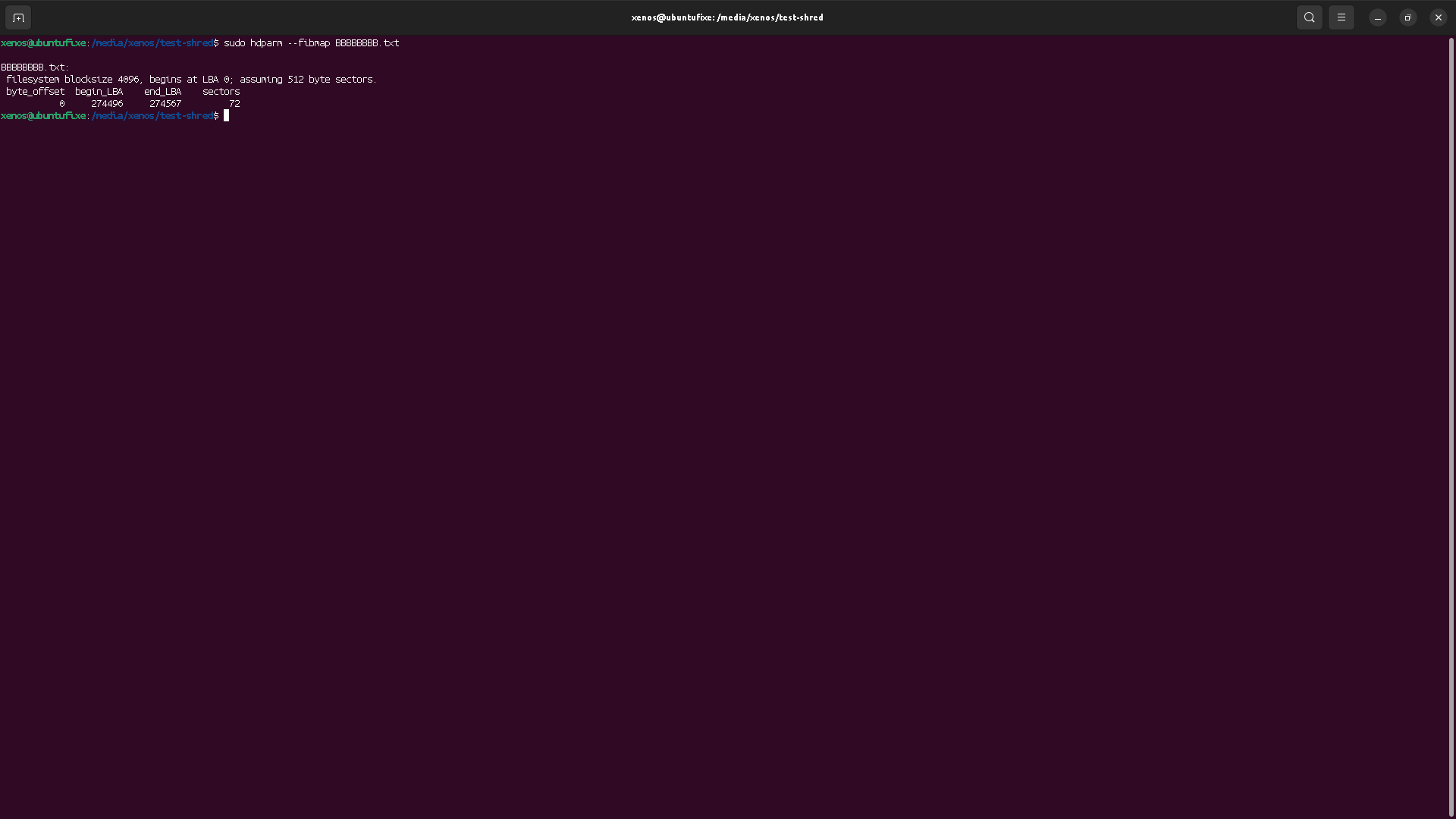
LBA means Logical Block Address .
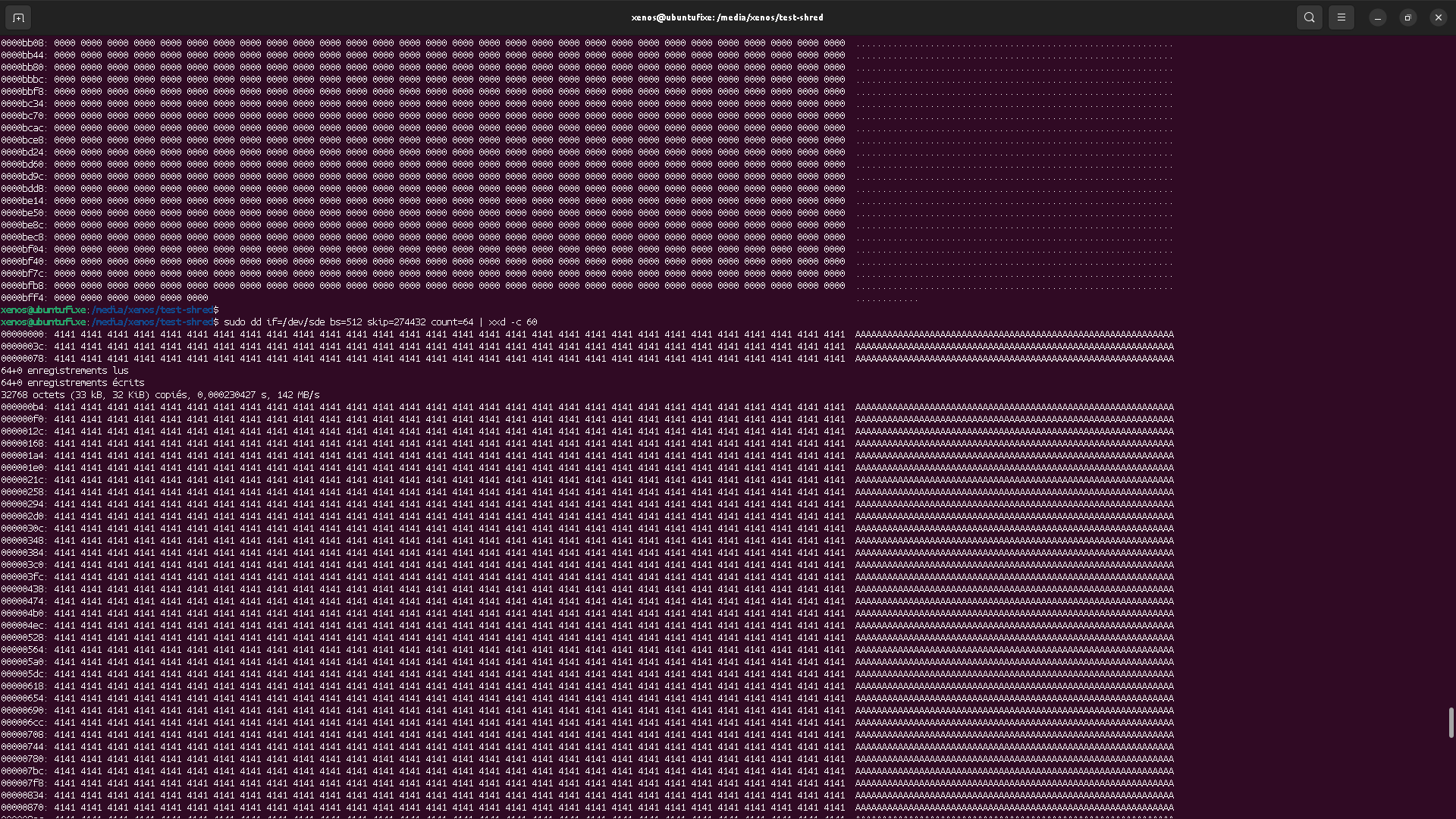
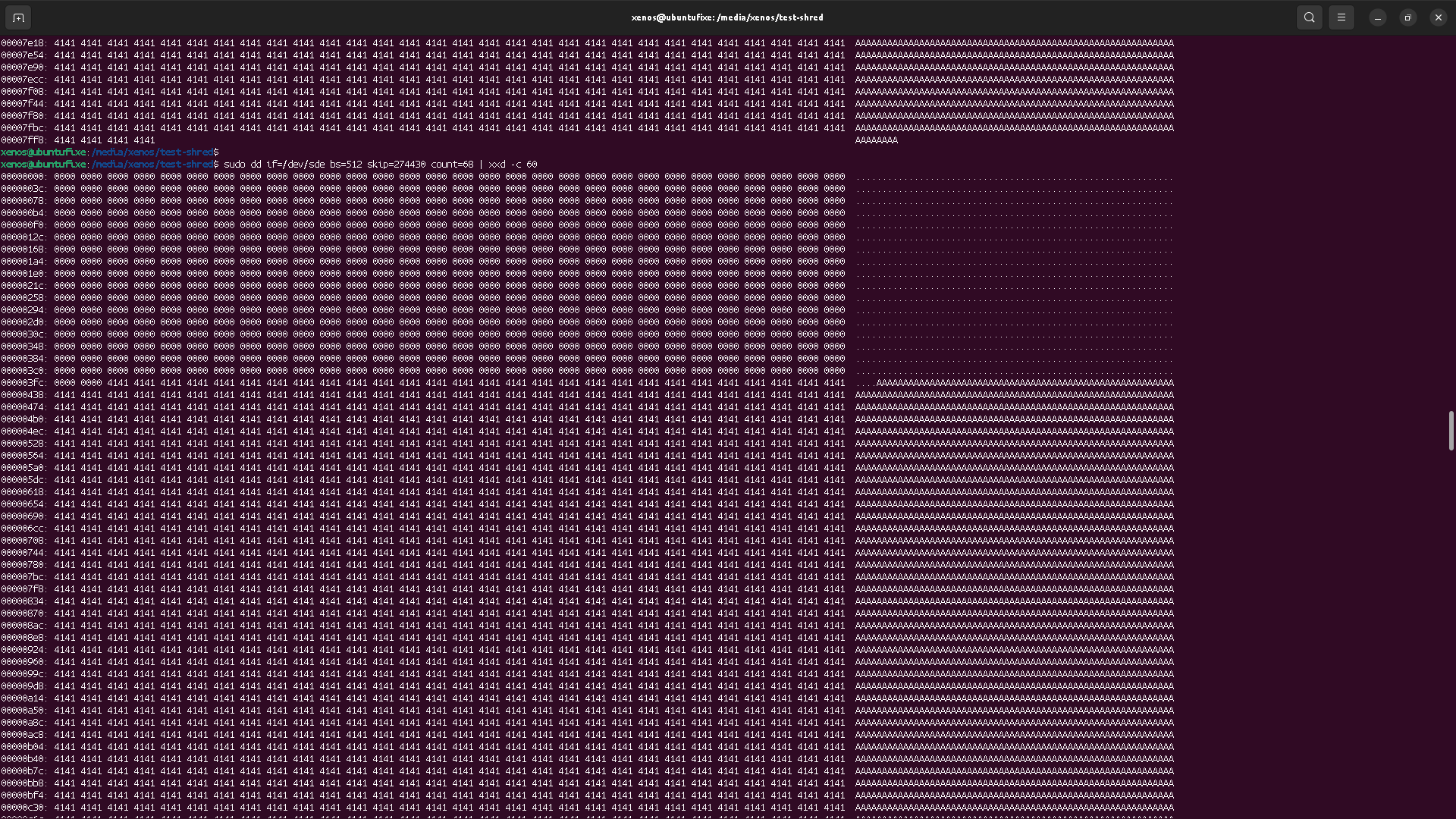
That means the file content has been stored in a different place than the previous one. It explains why, at the previous place, we still see the old data. They were not erased by the OS, and instead, the OS stored the file content in other sectors, somewhere else on the block device.
Altho I don't have the direct link to the documentation (lazy, you know!), this is actually an expected behavior:
when saving a file after we made changes in nano, the text editor does not overwrite the existing file
directly, but instead, makes a new one to save the changes to, and remove the old one leading the OS
to reallocate the content location on the block device.
The blocks allocated for the original file's content are now unallocated (but not erased),
and some unallocated blocks are not allocated to store the new file's content.
There might exist some file systems or OS that would overwrite any block when unallocating it to drastically reduce the data leak risk. But in such case, these FS or OS would have far weaker I/O performance.
This is a very common behavior of software in general, which are not guarantiing to overwrite the original file, and can often save the changes in a different location. Thos, this could also be the OS doing some sort of "software-based wear leveling" (see above), but I actually doubt so.
But also, caches
So, if we check the new content location, we should see the data, right?

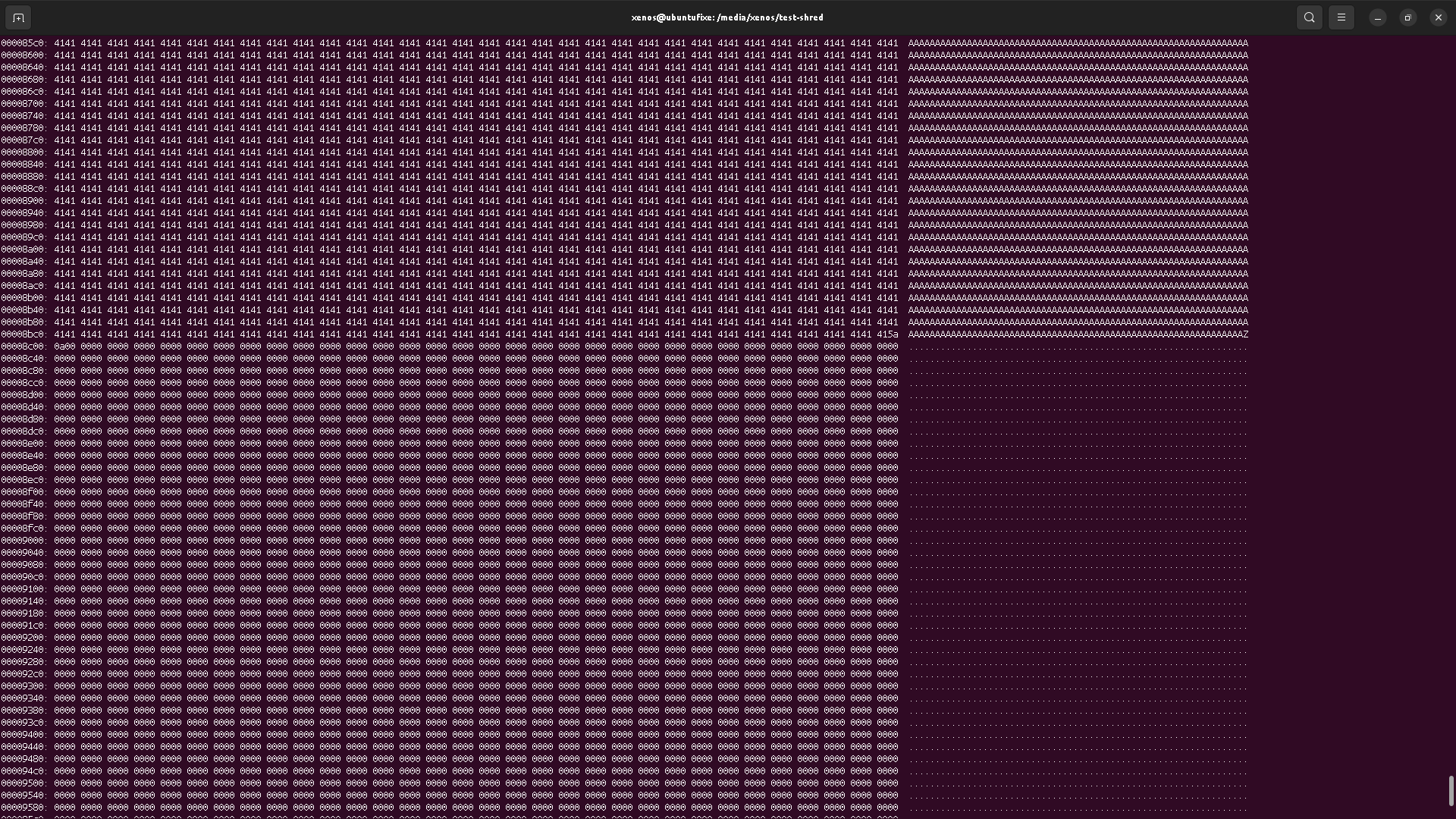
This is actually not a surprising result, because OS (kernel) have written caches on block devices, and this is somehow the same reason why you should unmount USB removable storages properly (by unmounting them first) to avoid data loss. If you don't do so, data "written" to removable device might actually be written in the cache, and not flushed to the physical drive, leading to data loss if that drive is physically removed without first telling the kernel (OS) that it should flush cache on it first.
So what we have learnt here is that editing software may leak data by reallocation the file content to new blocks/sectors, meaning the actual file content can appear several times on the drive, in the unallocated space.
Short files
We have done the tests, so far, with a file those content matches exactly the block size (4k) or one of its multiples. But what if we have a large file (say, 4k) and we shorten it (to 1k)?
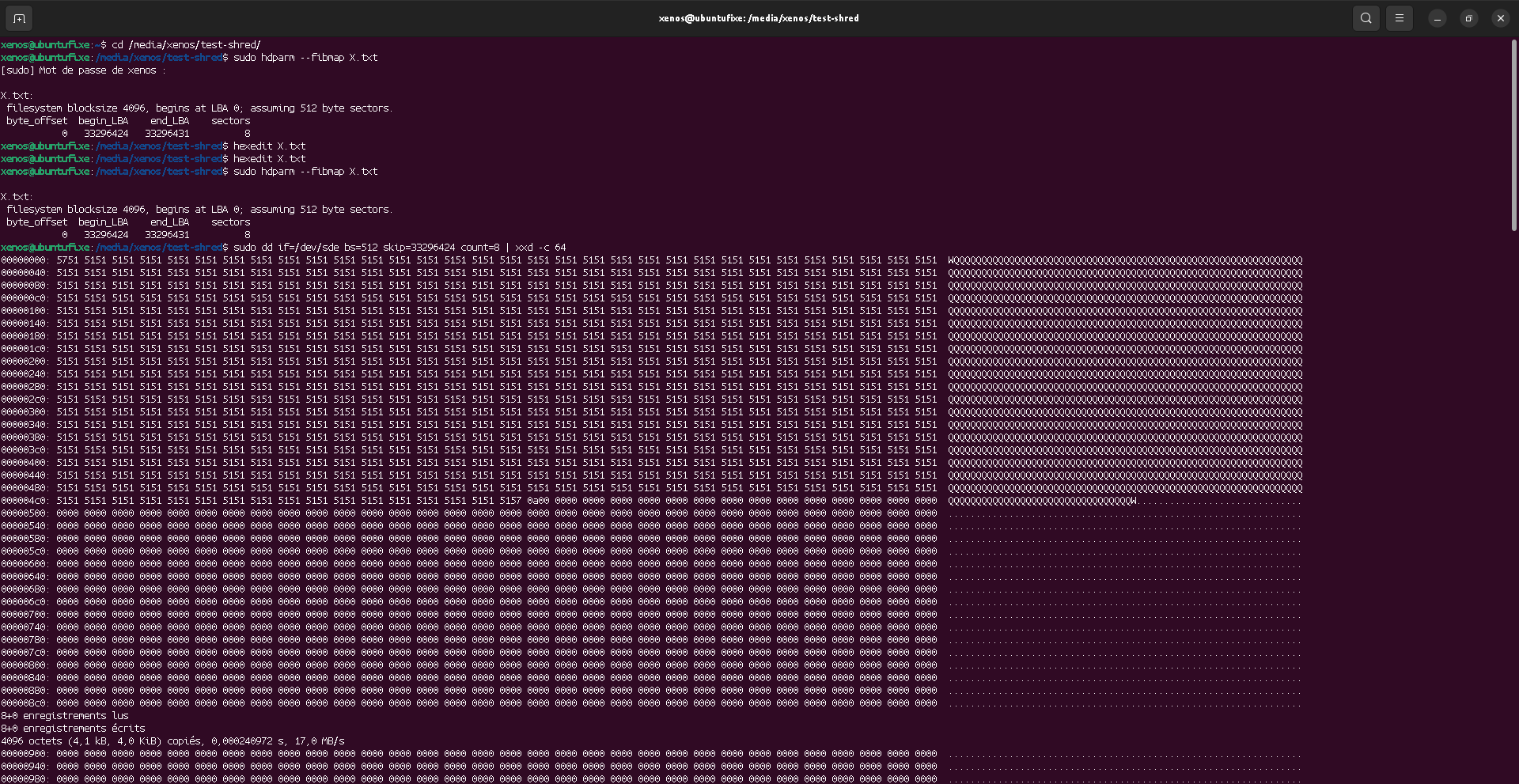
Now, what happens if we reduce the text inside the file? The text will not fill the block, but will the old text remain (in that block) or will it be erased?
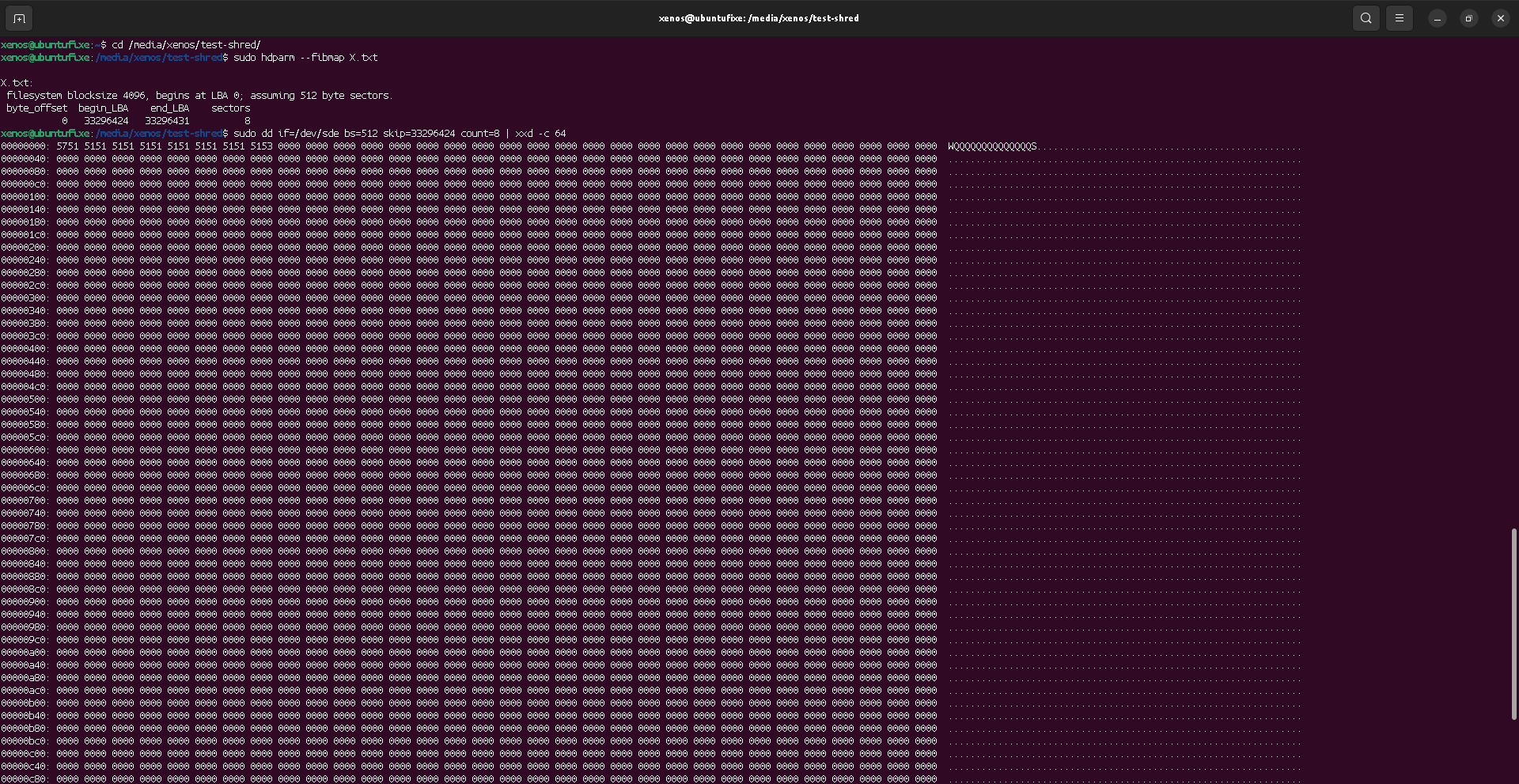
It seems that the rest of the text is erased (with zeroes). But, I would actually not rely on that, since I'm unsure if it's a kernel-level action, or if it depends on the software used (here, hexedit, because nano would have reallocated the blocks on the device, making the test useless).
What might also happen (depending on software? kernel? OS? file system? I don't know) is given below as an example.


This is a forged example: in reality and as seen above, using nano would allocate a new range of blocks, and so, the password would remain somewhere on the disk, in the unallocated blocks

Again, this example is forged, so I cannot very tell if the rest of the block is always
reset to zeroes by the kernel/OS, or if it is up to the software to do so.
In any case, I would not rely on this as a DLP, and I would consider that the blocks allocated
for a file might have trailing data in them,
and could contain sensitive information that were supposed to be removed from the files.
Shredding the data
Now, let's remove our previous file (with rm), and create a new one with a new content. Then, we'll try to see if we can completly destroy its data, making the actual data content unrecoverable.
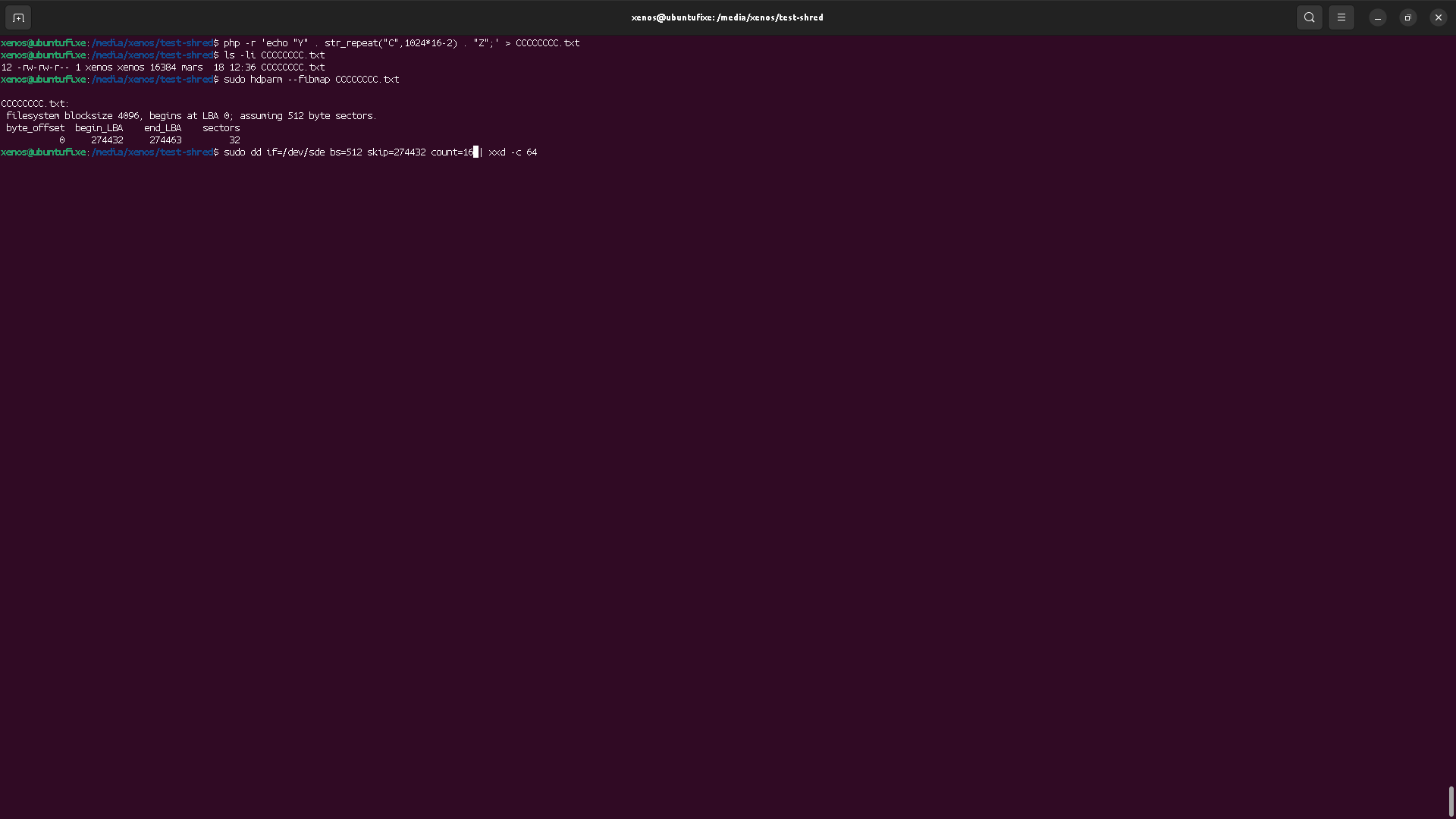
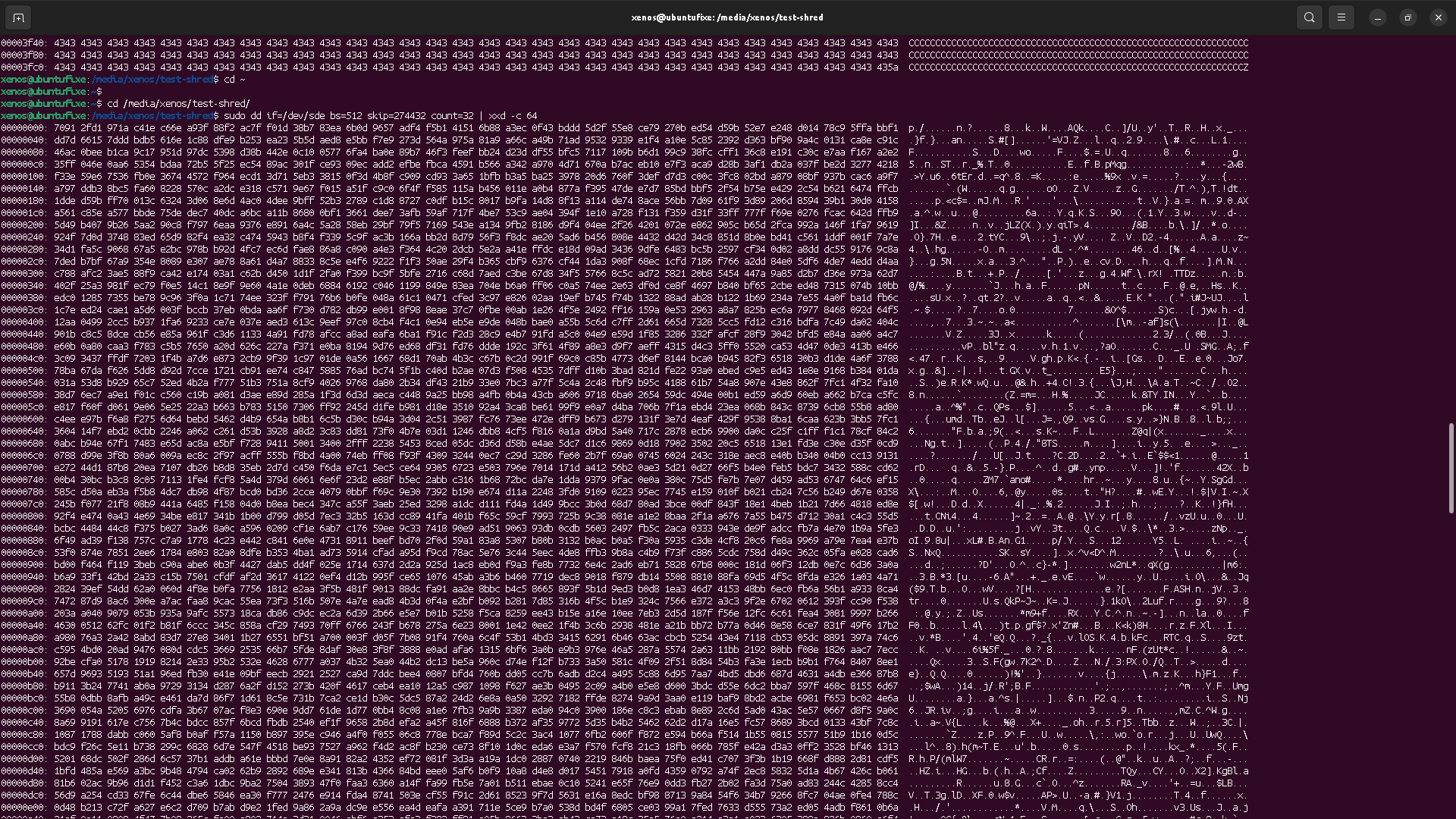
We can see that this new file content is located at the same block adress that the previous file, which we have deleted. That means the OS has allocated these blocks again to store some data content.
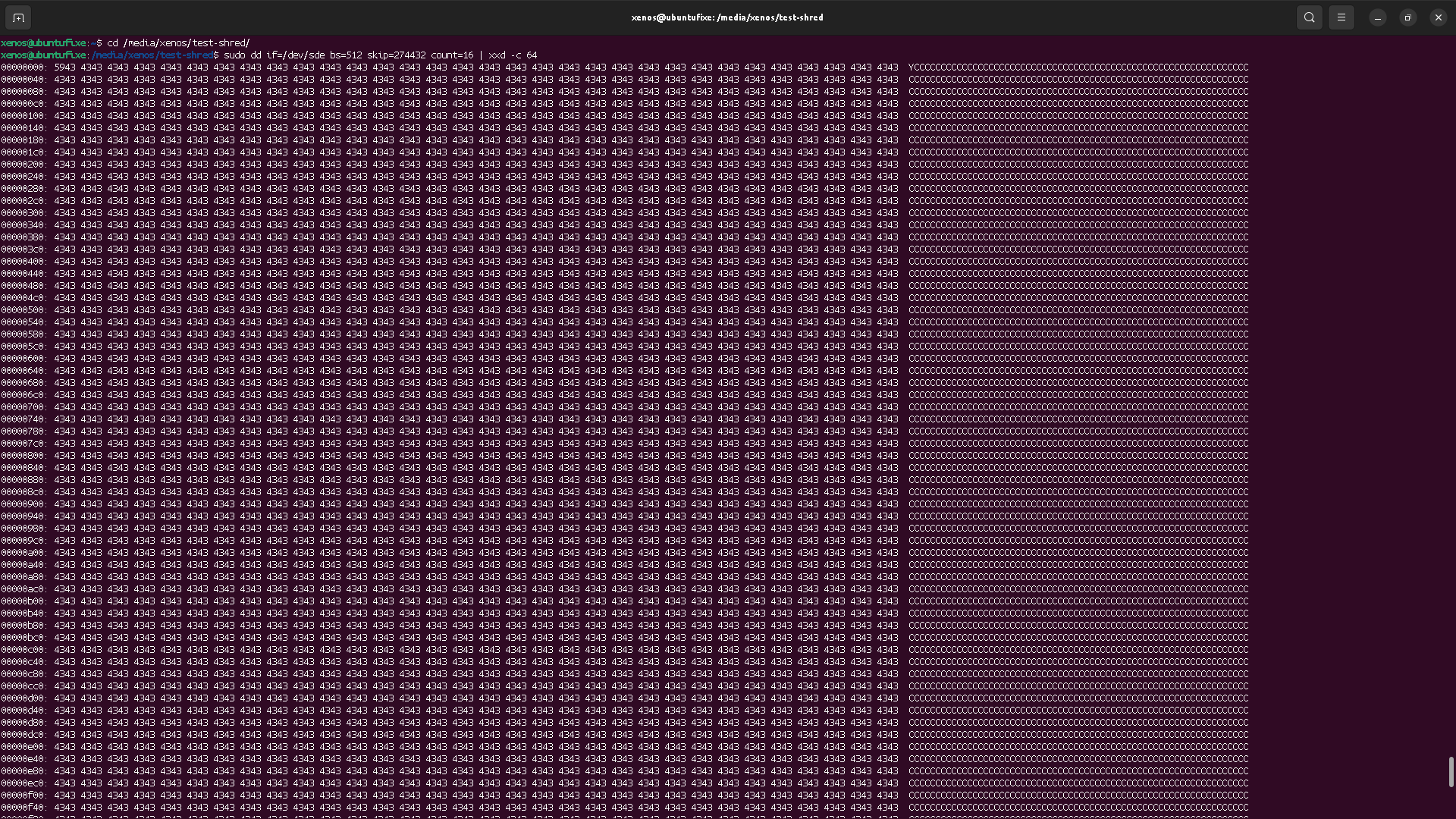
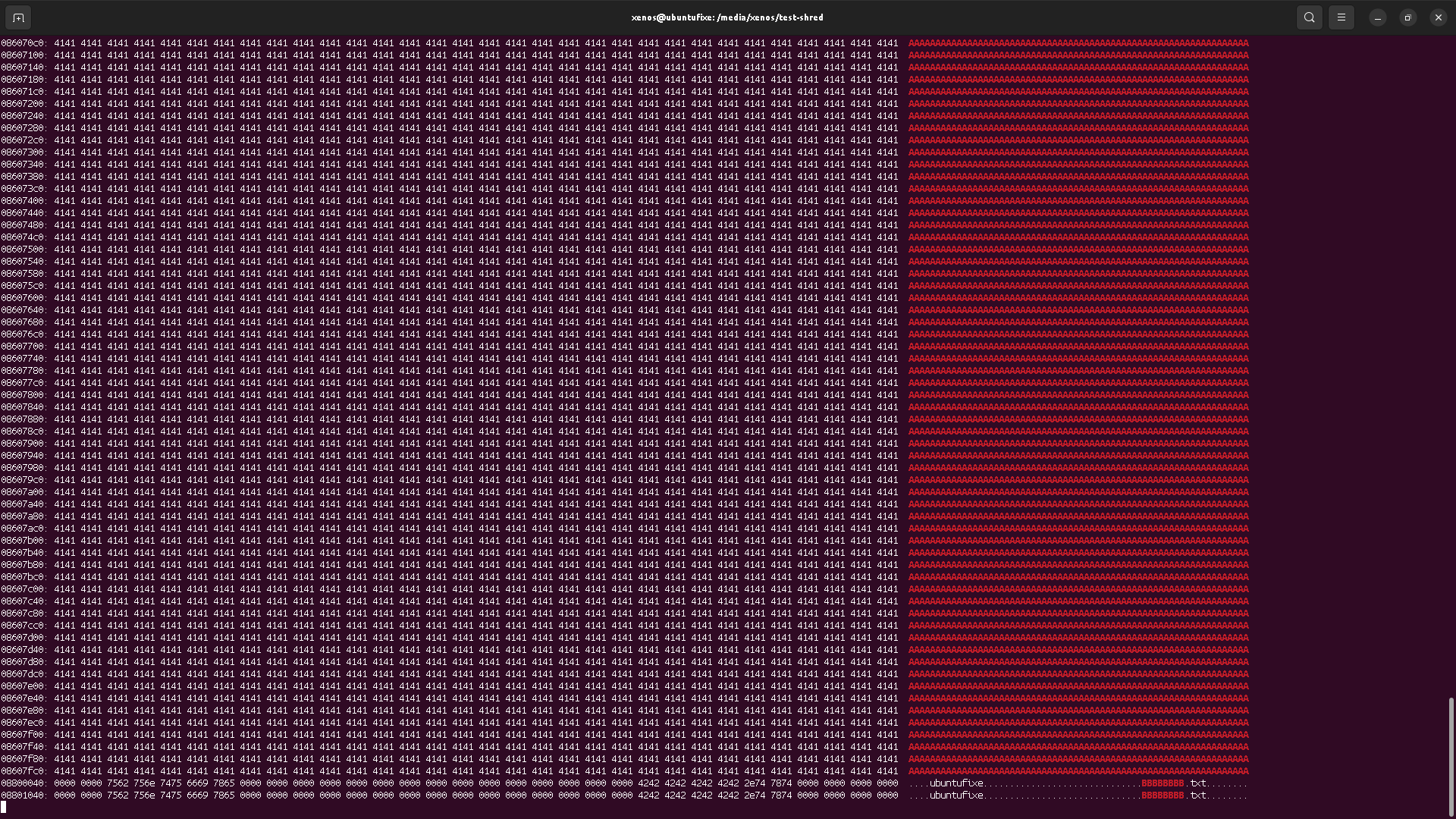
Using the shred, the file content seems properly destroyed,
so long you have unmounted the device to avoid any cache latency issue.
"Wear Leveling"?
Last thing, what about that "wear leveling" we mentionned at the start of this post? Does this mean the content of a shreded file could remain somewhere on the disk? Let's check.
If we supposed that "wear leveling" stores data at a different physical place on the disk, can we spot that? We could suppose that the Logical Block Adressing is not directly mapped to the physical blocks (PB) on the device. For instance, it means that block at LBA 1 could be stored in block at PB 42. But if that's so, where is stored LBA 42? It cannot be stored at PB 42 (already mapped and occupied), so it must be stored somewhere else, like PB 33. But then, where is stored LBA 33? And so on…
With the pigeonhole principle, that means a wear-leveling will always "swap" blocks from the mapping, and never add/remove blocks from it. If a swap is done, then by reading the entire disk, we should cross the path of both the swapped blocks, and we should see the data remapped by wear-leveling.
Lost? Here is an example: we have a file content stored at LBA 42, and we overwrite it with random data using shred. Suppose wear-leveling is storing the random data somewhere else on the physical drive (meaning the original data are still readable from the physical blocks), then if we read the entire drive, we should see the original data somewhere. If we don't see them, then wear leveling is not happening.

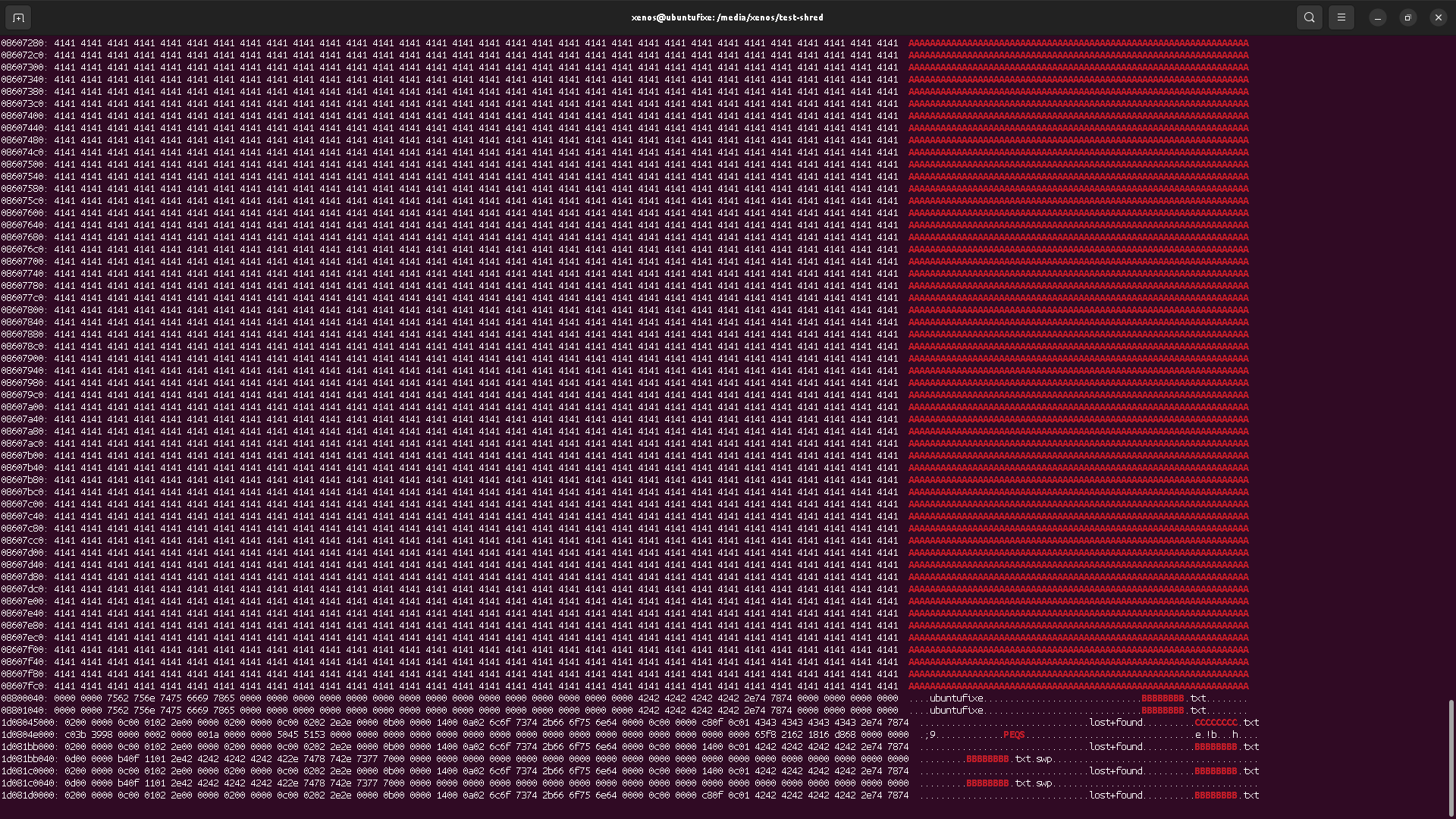
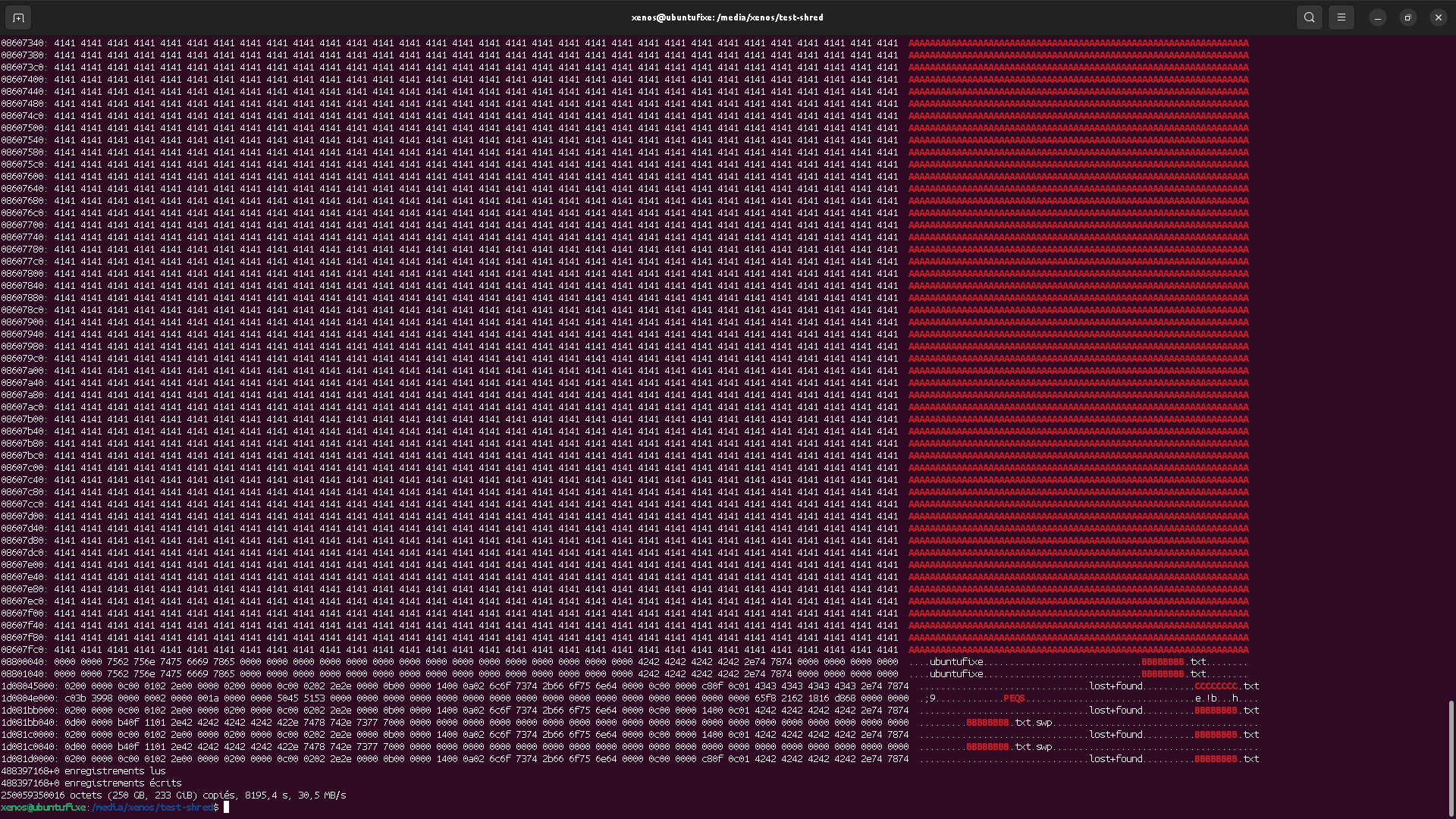
That means either the wear leveling is not existing on this drive, or, it's the OS/kernel responsibility.
Maybe I'm mistaking here and very advanced skilled attacker could extract data from physical blocks, but I highly doubt so (except by using the physical redundancy and error correction maybe). Still, but the very vast majority of data, this means shred properly destroyed the data content, but the file names might remain in copies of the file tables.
What about the mecanical drives?
The "wear leveling" of the introduction was aimed for SSD (to enhance their life duration) but is it applicable to mechanical drives?
So no matter the drive type, it seems the blocks allocation would change and rotate for any actual drive technology.
Still, I also have some drives for which I delete and add files on a regular basis
(system drives with regular system life). And, along time, the compressed size of a raw copy of the drive image
does not change, meaning that the allocated blocks sounds to always remain the same.
Hence, it looks like the block allocations may "rotate" and change,
but I would not rely on this behavior in general.
Conclusion
The main points we have see so far are
- A file on a device may leak its data in all unallocated space throught its lifecycle, meaning tons of hidden copies of the file might exist on the storage device
- Deleting a file (rm) does not clear its content on the physical device, and the content can be recovered quiet easily (the less fragmented, the easier)
- shred is finely erasing the data content, by replacing the allocated blocks content with random data
- The file names might be recovered from copies of the file tables
- Wear-leveling does not seem to impact the recovery of delete files data, but OS blocks reallocation might make foresnics harder
- Behavior may depend on OS and Filesystem, so this may differ for non ext4 system
So the best for DLP is to zero the full device using either
dd if=/bin/zero of=/dev/sd* or, for more critical data, shred -zn 5 /dev/sd* to fill the disk with random data.
The number of iterations (5 here) might depend on the legal recommandations
(so far I remember, 3 is often enough for
NIST purge).
Bonuses
Crypto Erasing
Is it OK for DLP to just delete the encryption key if the device is encrypted?
I would say: no, because how can you be sure you have erased all copies of that key? We have seen that the file table is duplicated (BBBBBBB and CCCCCCC file names persist at the middle of the disk in the file tables backups), so the encryption kay could remain somewhere (not to mention a malicious user might have exfiltrated that key too).
Partitions
Can I shred/zero a partition and not the entire disk?
I would say "yes", because the partition should have a single block range and so should not spread around the physical device, but I'm not 100% sure. So I would still advice to shred/zero the entire disk in case you want to protect your data from leaks.
TL;DR
What's the easiest purge process to do?
sudo shred -zun 10 ./the-file-to-pruge.txt if the file was never edited/opened.
sudo dd if=/bin/zero of=/dev/sd* bs=120M (bs is optional, and just for speedness) or
sudo shred -zn 5 /dev/sde for paranoiacs.